pod创建
命令创建
kubectl run nginx --image=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nginx:latest
pod/nginx created
YAML创建
cat pod.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
spec:
containers:
- name: c1
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/polinux/stress:latest
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
# polinux/stress这个镜像用于压力测试,在启动容器时传命令与参数就是相当于分配容器运行时需要的压力
kubectl apply -f pod.yml
镜像拉取策略
由imagePullPolicy参数控制
- Always : 不管本地有没有镜像,都要从仓库中下载镜像
- Never : 从来不从仓库下载镜像, 只用本地镜像,本地没有就算了
- IfNotPresent: 如果本地存在就直接使用, 不存在才从仓库下载
默认的策略是:
- 当镜像标签版本是latest,默认策略就是Always
- 如果指定特定版本默认拉取策略就是IfNotPresent。
pod资源限制
spec:
containers:
- name: c1
image: polinux/stress
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
cpu: "500m"
requests:
memory: "100Mi"
cpu: "250m"
如果内存不够,这个pod状态变为OOMKilled,因为它是内存不足所以显示Container被杀死
pod重启策略
Always:表示容器挂了总是重启,这是默认策略
OnFailures:表容器状态为错误时才重启,也就是容器正常终止时才重启
Never:表示容器挂了不予重启
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启...... 依次类推
pod调度
pod调度流程

1. 通过kubectl命令应用资源清单文件(yaml格式)向api server 发起一个create pod 请求
2. api server接收到pod创建请求后,生成一个包含创建信息资源清单文件
3. apiserver 将资源清单文件中信息写入etcd数据库
4. Scheduler启动后会一直watch API Server,获取 podSpec.NodeName为空的Pod,即判断pod.spec.Node == null? 若为null,表示这个Pod请求是新的,需要创建,因此先进行调度计算(共计2步:1、过滤不满足条件的,2、选择优先级高的),找到合适的node,然后将信息在etcd数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
5. kubelet 通过watch etcd数据库(即不停地看etcd中的记录),发现有新的Node出现,如果这条记录中的Node与所在节点编号相同,即这个Pod由scheduler分配给自己,则调用node中的Container Runtime,进而创建container,并将创建后的结果返回到给api server用于更新etcd数据库中数据状态。
调度约束
我们为了实现容器主机资源平衡使用, 可以使用约束把pod调度到指定的node节点
- nodeName 用于将pod调度到指定的node名称上
- nodeSelector 用于将pod调度到匹配Label的node上
nodeName
nodeName: master01 # 通过nodeName调度到master01 节点
nodeSelector
spec:
nodeSelector: # nodeSelector节点选择器
bussiness: game # 指定调度到标签为bussiness=game的节点
containers:
- name: nginx
image: nginx:1.15-alpine
node 节点亲和性
Node 节点亲和性针对的是 pod 和 node 的关系,Pod 调度到 node 节点的时候匹配的条件
requiredDuringSchedulingIgnoredDuringExecution 硬亲和性
spec:
containers:
- name: myapp
image: nginx
affinity: #用于控制Pod调度的亲和性和反亲和性规则。
nodeAffinity: #控制Pod如何调度到节点上。
requiredDuringSchedulingIgnoredDuringExecution: # 表示在调度时必须满足的条件,在Pod执行期间可以忽略。
nodeSelectorTerms: #包含一个或多个匹配表达式,用于描述节点必须满足的条件。
- matchExpressions: #包含一组键、操作符和值的列表,用于描述节点的标签。
- key: zone #节点标签的键。
operator: In #操作符,可以是 In, NotIn, Exists, DoesNotExist, Gt, Lt
values: ##一个或多个字符串值。
- foo
- bar
我们检查当前节点中有任意一个节点拥有 zone 标签的值是 foo 或者 bar,就可以把 pod 调度到这个 node 节点的 foo 或者 bar 标签上的节点上
preferredDuringSchedulingIgnoredDuringExecution 软亲和性
软亲和性是可以运行这个 pod 的,尽管没有运行这个 pod 的节点定义的标签
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity: ##用于控制Pod调度的亲和性和反亲和性规则。
nodeAffinity: ##控制Pod如何调度到节点上
preferredDuringSchedulingIgnoredDuringExecution: ##表示在调度时偏好但不强制的条件,在Pod执行期间可以忽略。
- preference: ##包含一个或多个匹配表达式,用于描述节点应该满足的条件
matchExpressions: ##包含一组键、操作符和值的列表,用于描述节点的标签
- key: zone1 #节点标签的键
operator: In #操作符,可以是 In, NotIn, Exists, DoesNotExist, Gt, Lt
values:
- foo1
- bar1
weight: 60 #用于描述偏好的权重,范围从 1 到 100。权重越高,调度器越倾向于将Pod调度到匹配的节点上。
Pod 节点亲和性
pod 自身的亲和性调度有两种表示形式:
podaffinity:pod 和 pod 更倾向腻在一起,把相近的 pod 结合到相近的位置,如同一区域,同一机架,这样的话 pod 和 pod 之间更好通信,比方说有两个机房,这两个机房部署的集群有 1000 台主机,那么我们希望把 nginx 和 tomcat 都部署同一个地方的 node 节点上,可以提高通信效率;
podunaffinity:pod 和 pod 更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个 pod 随机选则一个节点,做为评判后续的 pod 能否到达这个 pod 所在的节点上的运行方式,这就称为 pod 亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义 pod 亲和性时需要有一个前提,哪些 pod 在同一个位置,哪些 pod 不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置, 节点名称不相同的表示不是一个位置。
亲和性
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟着它走:
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app2: myapp2
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity: #这部分定义了Pod之间的亲和性策略。
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和性
- labelSelector: #选择具有特定标签的Pod。
matchExpressions:
- {key: app2, operator: In, values: ["myapp2"]}
topologyKey: kubernetes.io/hostname #指定节点属性键,这里是节点名称。
上面表示创建的 pod 必须与拥有 app=myapp 标签的 pod 在一个节点上
第一个 pod 调度到哪,第二个 pod 也调度到哪,这就是 pod 节点亲和性
反亲和性
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟它调度节点相反
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity: #这部分定义了Pod之间的亲和性策略。
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和性
- labelSelector: #选择具有特定标签的Pod。
matchExpressions:
- {key: app1, operator: In, values: ["myapp1"]}
topologyKey: kubernetes.io/hostname #指定节点属性键,这里是节点名称。
topologykey的作用
topologyKey作用:
节点标签:节点必须具有这个标签键,并且具有具体的值。
反亲和性:带有相同应用标签的 Pod 不会被调度到具有相同标签的节点上。
亲和性:如果使用的是亲和性配置,则带有相同应用标签的 Pod 将被尽可能调度到具有相同标签的节点上。
污点、容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod;
taints 是键值数据,用在节点上,定义污点;
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点
pod 亲和性是 pod 属性;但是污点是节点的属性,污点定义在 nodeSelector 上
污点等级
effect 用来定义对 pod 对象的排斥等级(效果): NoSchedule: 仅影响 pod 调度过程,当 pod 能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的 pod 不能容忍了,那这个 pod 会怎么处理,对现存的 pod 对象不产生影响 NoExecute: 既影响调度过程,又影响现存的 pod 对象,如果现存的 pod 不能容忍节点后来加的污点,这个 pod 就会被驱逐 PreferNoSchedule: 最好不,也可以,是 NoSchedule 的柔性版本
容忍度匹配
在 pod 对象定义容忍度的时候支持两种操作:
1.等值密钥:key 和 value 上完全匹配
2.存在性判断:key 和 effect 必须同时匹配,value 可以是空
在 pod 上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,
每一个污点都能被容忍,才能完成调度,如果不能容忍怎么办,那就需要看 pod 的容\忍度了
kubectl describe nodes master01
Taints: node-role.kubernetes.io/master:NoSchedule
上面可以看到 master 这个节点的污点是 Noschedule
所以我们创建的 pod 都不会调度到 master01 上,因为我们创建的 pod 没有容忍度
案例
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
tolerations: # Pod 可以容忍的污点列表,允许 Pod 被调度到具有相应污点的节点上。
- key: "node-type" #污点的键名。这里为 node-type
operator: "Equal" #用于匹配值的操作符。Equal 表示等同于
value: "production" #与键关联的值。这里为 production
effect: "NoSchedule" #污点的效果,通常有 NoSchedule, PreferNoSchedule, 和 NoExecute。NoExecute 表示如果 Pod 不能容忍此污点,它将被驱逐。
Pod生命周期
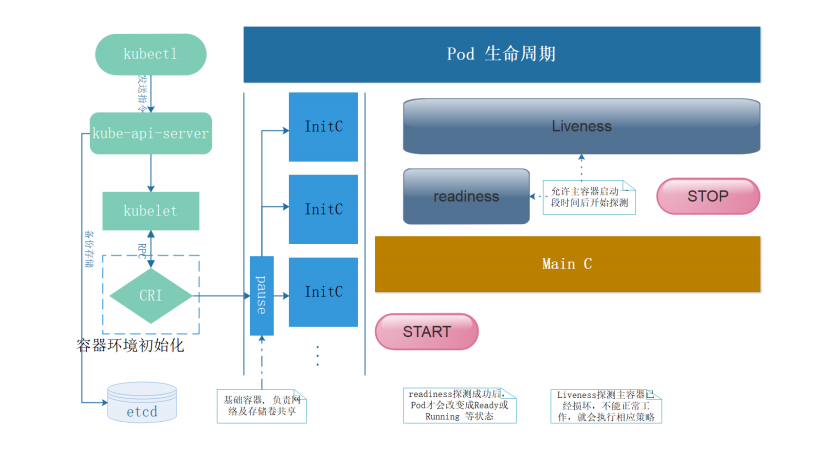
健康检查
健康检查方式
Liveness Probe(存活状态探测): 指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为 Success。
readiness Probe(就绪型探测): 指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为 Success。注:检查后不健康,将容器设置为Notready;如果使用service来访问,流量不会转发给此种状态的pod
startup Probe: 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器,而容器依其 重启策略进行重启。 如果容器没有提供启动探测,则默认状态为 Success。
探测方式
Exec:执行命令
HTTPGet: http请求某一个URL路径
TCP:tcp连接某一个端口
gRPC: 使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC健康检查。 如果响应的状态是 “SERVING”,则认为诊断成功。 gRPC 探针是一个 alpha 特性,只有在你启用了 “GRPCContainerProbe” 特性门控时才能使用。
readiness+liveness综合案例
vim pod-readiness-liveiness.yml
apiVersion: v1
kind: Pod
metadata:
name: readiness-liveness-httpget
namespace: default
spec:
containers:
- name: readiness-liveness
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 5 # pod启动延迟5秒后探测
periodSeconds: 5 # 每5秒探测1次
post-start
容器启动前执行的命令
apiVersion: v1
kind: Pod
metadata:
name: poststart
namespace: default
spec:
containers:
- name: poststart
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
lifecycle: # 生命周期事件
postStart:
exec:
command: ["mkdir","-p","/usr/share/nginx/html/haha"]
pre-stop
容器终止前执行的命令
apiVersion: v1
kind: Pod
metadata:
name: prestop
namespace: default
spec:
containers:
- name: prestop
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
lifecycle: # 生命周期事件
preStop: # preStop
exec:
command: ["/bin/sh","-c","sleep 60000000"] # 容器终止前sleep 60000000秒
pod状态
| 状态 | 描述 |
|---|---|
| Pending(悬决) | Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。 |
| Running(运行中) | pod已经绑定到一个节点,并且已经创建了所有容器。至少有一个容器正在运行中,或正在启动或重新启动。 |
| completed(完成) | Pod中的所有容器都已成功终止,不会重新启动。 |
| Failed(失败) | Pod的所有容器均已终止,且至少有一个容器已在故障中终止。也就是说,容器要么以非零状态退出,要么被系统终止。 |
| Unknown(未知) | 由于某种原因apiserver无法获得Pod的状态,通常是由于Master与Pod所在主机kubelet通信时出错。 |
| CrashLoopBackOff | 多见于CMD语句错误或者找不到container入口语句导致了快速退出,可以用kubectl logs 查看日志进行排错 |