CNI插件类别
- main,实现某种特定的网络功能,如loopback、bridge、macvlan、ipvlan
- meta,自身不提供任何网络实现,而是调用其他插件,如flannel
- ipam,仅用于分配IP地址,不提供网络实现
常见网络方案
Flannel:提供叠加网络,基于linux TUN/TAP,使用UDP封装IP报文来创建叠加网络,并借助etcd维护网络分配情况
Calico:基于BGP的三层网络,支持网络策略实现网络的访问控制。在每台机器上运行一个vRouter,利用内核转发数据包,并借助iptables实现防火墙等功能
- kube-router:K8s网络一体化解决方案,可取代kube-proxy实现基于ipvs的Service,支持网络策略、完美兼容BGP的高级特性
flannel简介
在 Kubernetes 集群中,跨节点 Pod 通信是 Flannel 等 CNI 插件的重要职责。
Pod同一节点通信直接通过cnio网桥转发,而pod跨节点通信需要借助 Overlay 网络(如 VXLAN)或 路由机制(如 Host-GW)实现。
Flannel提供叠加网络,基于linux TUN/TAP,使用UDP封装IP报文来创建叠加网络,并借助etcd维护网络分配情况
配置查看
flannel配置
我们在部署flannel的时候,有一个配置文件,在这个配置文件中的configmap中就定义了虚拟网络的接入功能。
cat /data/kubernetes/flannel/kube-flannel.yml #flannel的yaml文件,位置是自己定义的
kind: ConfigMap
...
data:
cni-conf.json: | cni插件的功能配置
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel", 基于flannel实现网络通信
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap", 来实现端口映射的功能
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: | flannel的网址分配
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan" 来新节点的时候,基于vxlan从network中获取子网
}
}
查看网络配置
cat /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
...
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
...
- --cluster-cidr=10.244.0.0/16
配置解析:
allocate-node-cidrs属性表示,每增加一个新的节点,都从cluster-cidr子网中切分一个新的子网网段分配给对应的节点上。这些相关的网络状态属性信息,会经过 kube-apiserver 存储到etcd中。
CNI配置
ls /etc/cni/net.d
10-flannel.conflist
cat 10-flannel.conflist
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
ls /opt/cni/bin
bandwidth bridge dhcp dummy firewall flannel host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan vrf
使用CNI插件编排网络,Pod初始化或删除时,kubelet会调用默认CNI插件,创建虚拟设备接口附加到相关的底层网络,设置IP、路由并映射到Pod对象网络名称空间
kubelet在/etc/cni/net.d目录查找cni json配置文件,基于type属性到/opt/cni/bin中查找相关插件的二进制文件,然后调用相应插件设置网络
网段配置
cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16 #定义 Flannel 管理的全局 Pod 网段(所有 Kubernetes Pod 的 IP 地址范围)
FLANNEL_SUBNET=10.244.0.1/24 #当前节点分配的子网,用于该节点上的 Pod
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
网段分配原理
集群的 kube-controller-manager 负责控制每个节点的网段分配
集群的 etcd 负责存储所有节点的网络配置存储
集群的 flannel 负责各个节点的路由表定制及其数据包的拆分和封装
flannel各个节点是平等的,仅负责数据平面的操作。网络功能相对来说比较简单。
flannel模型
| 模式 | 原理 | 性能 |
|---|---|---|
| VXLAN(默认) | pod与pod通过隧道封装原始数据包之后通信,不要求在同一个二层网络 | 中等 |
| Host-GW | pod与pod不经隧道封装而直接通信,要求各节点在同一个二层网络 | 高 |
VXLAN模型
环境准备
kubectl get pod -o wide
busybox1-5c99cfb6f4-kv9vl 1/1 Running 2 (3h9m ago) 23h 10.244.2.5 node02 <none> <none>
nginx-deployment-6b9d659f5f-9fxt9 1/1 Running 0 2d14h 10.244.1.4 node01 <none> <none>
两个容器在不同节点,busybox1(10.244.2.5)访问nginx(10.244.1.4)
图解
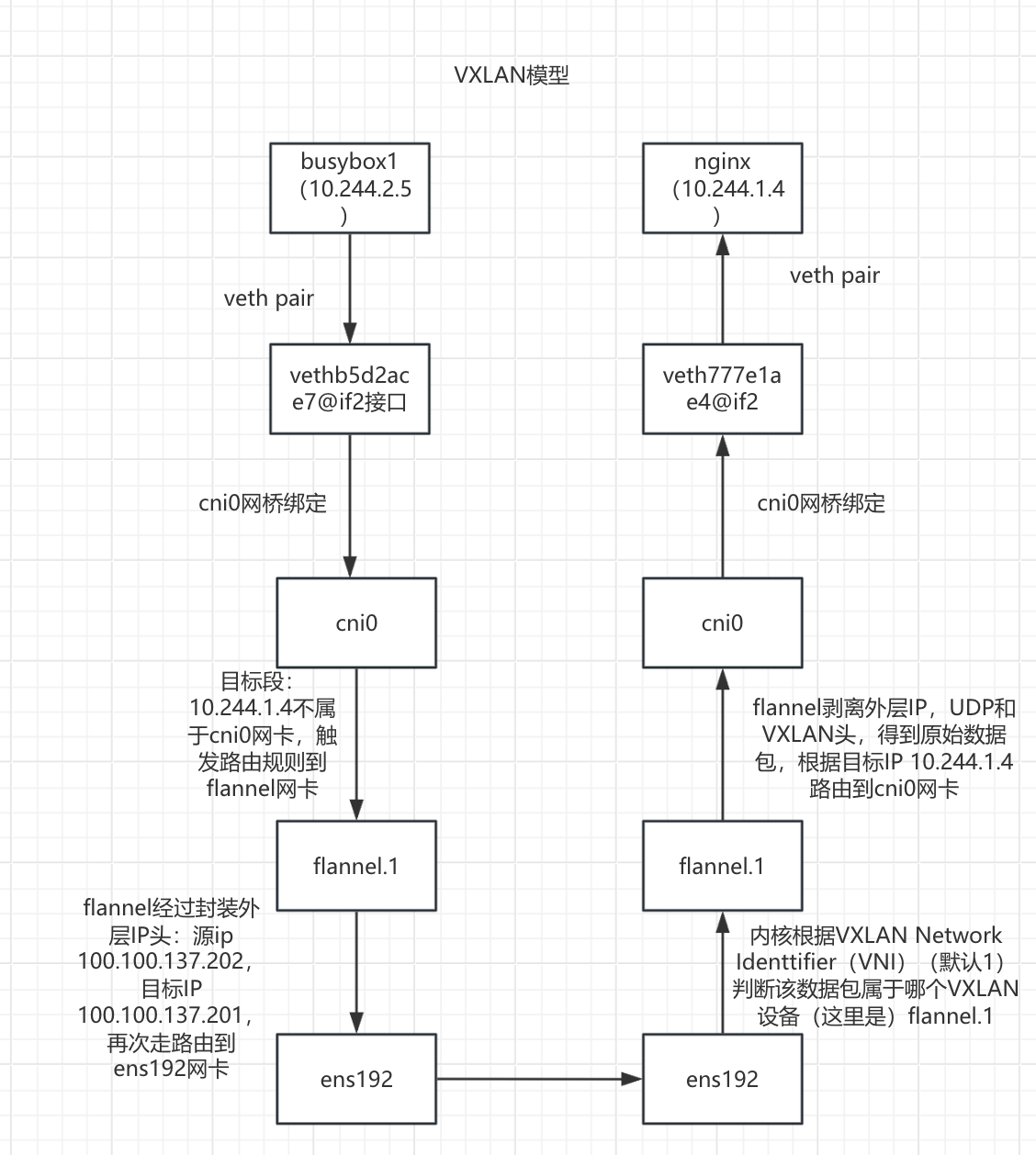
对于pod来说,它以为是通过 flannel.x -> vxlan tunnel -> flannel.x 实现数据通信,因为它们的隧道标识都是".1",所以认为是一个vxlan,直接路由过去了,没有意识到底层的通信机制。
注意: 由于这种方式,是对数据报文进行了多次的封装,降低了当个数据包的有效载荷。所以效率降低了
实践访问流程
busybox1(10.244.2.5)发起请求,目标IP:10.244.1.4
- busybox1(10.244.2.5)容器内部进行路由决策
ip route default via 10.244.2.1 dev eth0 #目标ip为10.244.1.4 数据包将会走默认路由 10.244.0.0/16 via 10.244.2.1 dev eth0 10.244.2.0/24 dev eth0 scope link src 10.244.2.5- 数据包从busybox1(10.244.2.5)容器内部通过veth pair 到达node02的 vethb5d2ace7@if2 接口
如何确认是vethb5d2ace7@if2 接口? kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- cat /sys/class/net/eth0/iflink 9 #表名接口的序号为9,然后在node02节点查看接口号 ip link show 9: vethb5d2ace7@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default link/ether 3e:a0:70:fd:42:33 brd ff:ff:ff:ff:ff:ff link-netnsid 3 由此确认busybox1(10.244.2.5)容器的eth0对应的是vethb5d2ace7@if2 接口- 数据包从vethb5d2ace7@if2 接口通过网桥到达cni0网桥
验证是真的通过网桥? 在node02查看网桥绑定情况: brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.7e4953c323ef no veth0accc413 veth3d4410be vethb5d2ace7 (关联busybox1容器的接口) vethb79abe30 可以看到确实是绑定状态数据包从cni0网卡路由到flannel.1网卡
查看node02的路由:
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink # 目标ip地址为10.244.1.4,数据包走此条路由到flannel.1网卡
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
数据包在flannel.1网卡进行VXLAN 封装
- FDB 表查询: node02 查询 FDB 表,获取目标 VTEP(
10.244.1.0/24)对应的物理 IP(100.100.137.201)和 MAC 地址:
# 查看 node02 的 FDB 表 bridge fdb show dev flannel.1 ca:0a:ef:ad:76:c6 dst 100.100.137.200 self permanent ae:74:1d:ff:13:f1 dst 100.100.137.201 self permanent #根据flannel为每个node分配的子网和目标ip进行匹配,找到 10.244.1.0/24 对应的条目是这条- 封装 VXLAN 数据包:
- 外层 IP 头:源 IP 100.100.137.202,目标 IP 100.100.137.201。
- 外层 UDP 头:源端口随机,目标端口 8472(Flannel 默认 VXLAN 端口)。
- VXLAN 头:VNI(VXLAN Network Identifier)为
1。 - 原始数据包:源 IP 10.244.2.5,目标 IP 10.244.1.4。
- FDB 表查询: node02 查询 FDB 表,获取目标 VTEP(
数据包经过flannel封装之后路由到ens192网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 #数据包经过flannel封装之后目标ip为100.100.137.201,走这条路由
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从node02的ens192网卡传输到node01的ens192网卡
- 数据包到达 node01 的ens192网卡进行识别
内核根据 VXLAN Network Identifier (VNI)(默认 1)判断该数据包属于哪个 VXLAN 设备(这里是 flannel.1)。
数据包到达 node01 flannel的网卡进行VXLAN解封装
node01 的 flannel.1 接口监听 UDP 端口 8472,接收数据包后:
- 验证 VNI 是否匹配(1)。
- 剥离外层 IP、UDP 和 VXLAN 头,得到原始数据包。
- 根据目标 IP 10.244.1.4 ,通过路由将数据包交给 cni0 网桥。
查看路由: ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1 #数据包解封装之后目标IP为10.244.1.4,走这个路由到cni0网桥 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
数据包从 cni0 网桥经由veth777e1ae4@if2接口转发到 nginx容器
cni网桥为什么经由veth777e1ae4@if2接口?
目标ip为10.244.1.4,此接口是 nginx容器内部eth0所对应的接口:
kubectl exec -it nginx-deployment-6b9d659f5f-9fxt9 -- cat /sys/class/net/eth0/iflink
8
然后在node01上查看网络接口:
ip link show
8: veth777e1ae4@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 52:f8:da:d0:33:33 brd ff:ff:ff:ff:ff:ff link-netnsid 1
cni0网卡为什么能到达veth777e1ae4@if2接口?
查看网桥绑定情况:
brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.4effc89fa2b4 no veth41cf9723
veth777e1ae4(关联nginx容器的接口)
可以看到确实是绑定的情况。
抓包验证
busybox1发送数据包:
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- sh
/ # ping 10.244.1.4 -c 1
PING 10.244.1.4 (10.244.1.4): 56 data bytes
64 bytes from 10.244.1.4: seq=0 ttl=62 time=1.191 ms
--- 10.244.1.4 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.191/1.191/1.191 ms
同时在node01上抓包:
tcpdump -i ens192 -en host 100.100.137.202 and udp port 8472
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
16:31:05.856351 00:0c:29:b2:ed:53 > 00:0c:29:b1:51:83, ethertype IPv4 (0x0800), length 148: 100.100.137.202.36012 > 100.100.137.201.otv: OTV, flags [I] (0x08), overlay 0, instance 1
6a:a7:9b:c0:79:82 > ae:74:1d:ff:13:f1, ethertype IPv4 (0x0800), length 98: 10.244.2.5 > 10.244.1.4: ICMP echo request, id 7168, seq 0, length 64
16:31:05.856996 00:0c:29:b1:51:83 > 00:0c:29:b2:ed:53, ethertype IPv4 (0x0800), length 148: 100.100.137.201.53839 > 100.100.137.202.otv: OTV, flags [I] (0x08), overlay 0, instance 1
ae:74:1d:ff:13:f1 > 6a:a7:9b:c0:79:82, ethertype IPv4 (0x0800), length 98: 10.244.1.4 > 10.244.2.5: ICMP echo reply, id 7168, seq 0, length 64
host-gw模型
配置flannel模型为host-gw模型
修改flannel的配置文件,将其转换为 host-gw 模型。
kubectl get cm -n kube-flannel
NAME DATA AGE
kube-flannel-cfg 2 3d1h
修改资源配置文件
kubectl edit cm kube-flannel-cfg -n kube-flannel
net-conf.json: |
{
"Network": "10.244.0.0/16",
"EnableNFTables": false,
"Backend": {
"Type": "host-gw"
}
}
重启pod
kubectl delete pod -n kube-flannel -l app
kubectl get pod -n kube-flannel
环境准备
kubectl get pod -o wide
busybox1-5c99cfb6f4-kv9vl 1/1 Running 2 (3h9m ago) 23h 10.244.2.5 node02 <none> <none>
nginx-deployment-6b9d659f5f-9fxt9 1/1 Running 0 2d14h 10.244.1.4 node01 <none> <none>
两个容器在不同节点,busybox1(10.244.2.5)访问nginx(10.244.1.4)
图解
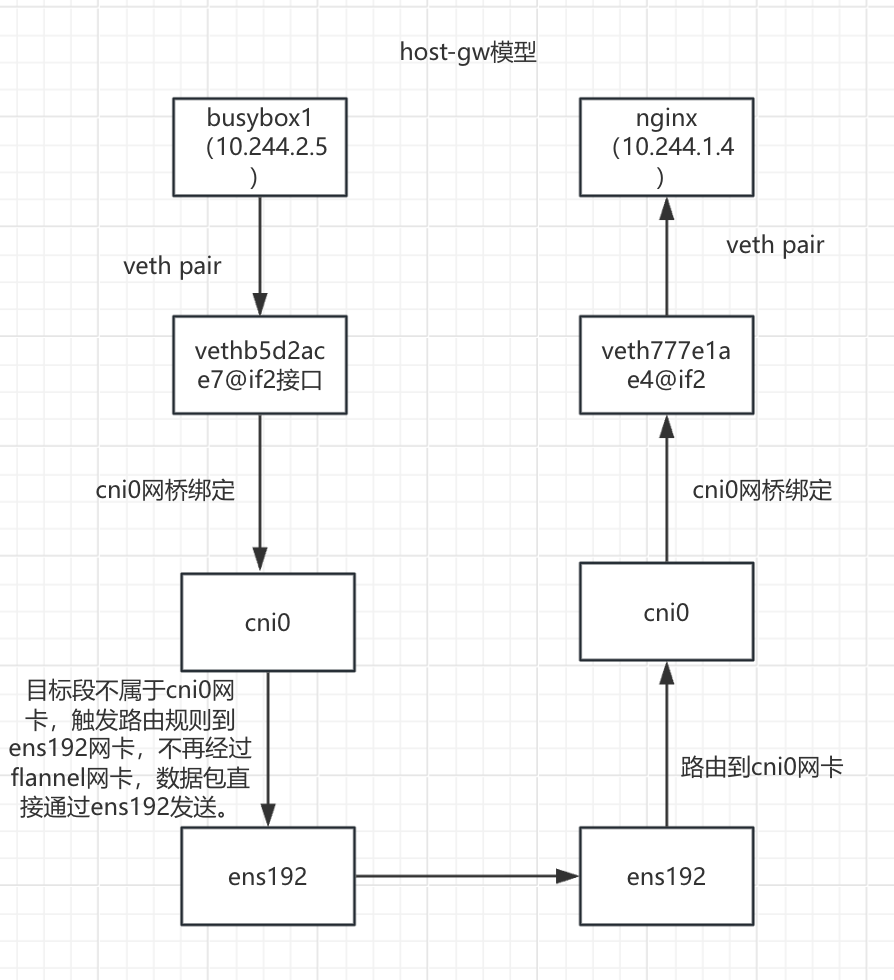
节点上的pod通过虚拟网卡对,连接到cni0的虚拟网络交换机上。pod向外通信的时候,到达CNI0的时候,不再直接交给flannel.1由flanneld来进行打包处理了。
cni0直接借助于内核中的路由表,通过宿主机的网卡交给同网段的其他主机节点
对端节点查看内核中的路由表,发现目标就是当前节点,所以交给对应的cni0,进而找到对应的pod。
实践访问流程
busybox1(10.244.2.5)发起请求,目标IP:10.244.1.4
- busybox1(10.244.2.5)容器内部进行路由决策
ip route default via 10.244.2.1 dev eth0 #目标ip为10.244.1.4 数据包将会走默认路由 10.244.0.0/16 via 10.244.2.1 dev eth0 10.244.2.0/24 dev eth0 scope link src 10.244.2.5- 数据包从busybox1(10.244.2.5)容器内部通过veth pair 到达node02的 vethb5d2ace7@if2 接口
如何确认是vethb5d2ace7@if2 接口? kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- cat /sys/class/net/eth0/iflink 9 #表名接口的序号为9,然后在node02节点查看接口号 ip link show 9: vethb5d2ace7@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default link/ether 3e:a0:70:fd:42:33 brd ff:ff:ff:ff:ff:ff link-netnsid 3 由此确认busybox1(10.244.2.5)容器的eth0对应的是vethb5d2ace7@if2 接口- 数据包从vethb5d2ace7@if2 接口通过网桥到达cni0网桥
验证是真的通过网桥? 在node02查看网桥绑定情况: brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.7e4953c323ef no veth0accc413 veth3d4410be vethb5d2ace7 (关联busybox1容器的接口) vethb79abe30 可以看到确实是绑定状态数据包从cni0网桥通过路由决策到达ens192网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 100.100.137.200 dev ens192
10.244.1.0/24 via 100.100.137.201 dev ens192 #目标ip为10.244.1.4 ,走这条路由到ens192网卡
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从node02的ens192网卡传输到node01的ens192网卡
- 数据包从node01的ens192网卡通过路由决策到达cni0网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 100.100.137.200 dev ens192
10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1 #目标ip为10.244.1.4 ,走这条路由到cni0网卡
10.244.2.0/24 via 100.100.137.202 dev ens192
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从 cni0 网桥经由veth777e1ae4@if2接口转发到 nginx容器
cni网桥为什么经由veth777e1ae4@if2接口?
目标ip为10.244.1.4,此接口是 nginx容器内部eth0所对应的接口:
kubectl exec -it nginx-deployment-6b9d659f5f-9fxt9 -- cat /sys/class/net/eth0/iflink
8
然后在node01上查看网络接口:
ip link show
8: veth777e1ae4@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 52:f8:da:d0:33:33 brd ff:ff:ff:ff:ff:ff link-netnsid 1
cni0网卡为什么能到达veth777e1ae4@if2接口?
查看网桥绑定情况:
brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.4effc89fa2b4 no veth41cf9723
veth777e1ae4(关联nginx容器的接口)
可以看到确实是绑定的情况。
抓包验证:
busybox1发送数据包:
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- sh
/ # ping 10.244.1.4 -c 1
PING 10.244.1.4 (10.244.1.4): 56 data bytes
64 bytes from 10.244.1.4: seq=0 ttl=62 time=1.191 ms
--- 10.244.1.4 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.191/1.191/1.191 ms
同时在node01上抓包:
tcpdump -i ens192 -nn host 10.244.2.5
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
16:56:46.838081 IP 10.244.2.5 > 10.244.1.4: ICMP echo request, id 12032, seq 0, length 64
16:56:46.838342 IP 10.244.1.4 > 10.244.2.5: ICMP echo reply, id 12032, seq 0, length 64