calico简介
Calico是一个开源的虚拟化网络方案,用于为云原生应用实现互联及策略控制.相较于 Flannel 来说,Calico 的优势是对网络策略(network policy),它允许用户动态定义 ACL 规则控制进出容器的数据报文,实现为 Pod 间的通信按需施加安全策略.不仅如此,Calico 还可以整合进大多数具备编排能力的环境,可以为 虚机和容器提供多主机间通信的功能。 Calico 本身是一个三层的虚拟网络方案,它将每个节点都当作路由器,将每个节点的容器都当作是节点路由器的一个终端并为其分配一个 IP 地址,各节点路由器通过 BGP(Border Gateway Protocol)学习生成路由规则,从而将不同节点上的容器连接起来.因此,Calico 方案其实是一个纯三层的解决方案,通过每个节点协议栈的三层(网络层)确保容器之间的连通性,这摆脱了 flannel host-gw 类型的所有节点必须位于同一二层网络的限制,从而极大地扩展了网络规模和网络边界。
配置查看
calico的CNI配置文件:
cat /etc/cni/net.d/10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"log_level": "info",
"log_file_path": "/var/log/calico/cni/cni.log",
"datastore_type": "kubernetes",
"nodename": "master01",
"mtu": 0,
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
calico部署完毕后,会生成一系列的自定义配置属性信息
kubectl api-versions | grep crd
crd.projectcalico.org/v1
该api版本信息中有大量的配置属性
kubectl get ippools
NAME AGE
default-ipv4-ippool 15m
查看这里配置的calico相关的信息
kubectl get ippools default-ipv4-ippool -o yaml
apiVersion: crd.projectcalico.org/v1
kind: IPPool
metadata:
annotations:
projectcalico.org/metadata: '{"uid":"321776f5-22ae-49cd-8924-1a9baef7edfb","creationTimestamp":"2025-05-07T05:03:11Z"}'
creationTimestamp: "2025-05-07T05:03:11Z"
generation: 1
name: default-ipv4-ippool
resourceVersion: "473394"
uid: 3fb4a469-fe7e-44b0-8d0a-3b8ca079633a
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 24
cidr: 10.244.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
可以看到这里的calico采用的模型是 ipip模型(默认),分配的网段是使我们指定的 cidr网段,而且子网段也是我们指定的 24位掩码
环境创建完毕后,会生成一个tunl0的网卡,所有的流量会走这个tunl0网卡
ifconfig tunl0
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1480
inet 10.244.0.1 netmask 255.255.255.255
tunnel txqueuelen 1000 (IPIP Tunnel)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 240 (240.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
calico模型中,默认使用的是tunl0虚拟网卡实现数据包的专线转发
calico结构
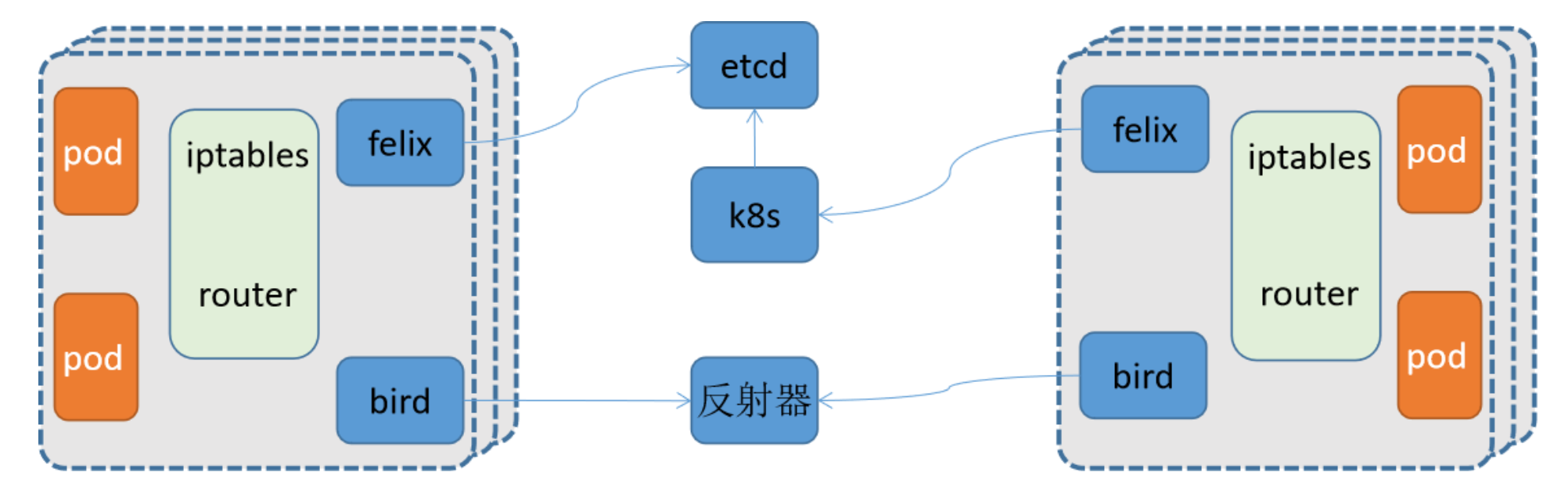
- Felix:每个节点都有,负责配置路由、ACL、向etcd宣告状态等
- BIRD:每个节点都有,负责把 Felix 写入Kernel的路由信息 分发到整个 Calico网络,确保 workload 连通
- etcd:存储calico自己的状态数据,可以结合kube-apiserver来工作
- Route Reflector:路由反射器,用于集中式的动态生成所有主机的路由表,非必须选项
Calico模型
| 模式 | 原理 | 性能 |
|---|---|---|
| IPIP(默认) | underlay network - BGP(三层虚拟网络解决方案),pod与pod通过隧道封装原始数据包之后通信 | 中等 |
| BGP | overlay network - IPIP(双层IP实现跨网段效果)、VXLAN(数据包标识实现大二层上的跨网段通信) | 高 |
IPIP模型
环境准备
kubectl get pod -o wide
busybox1-5c99cfb6f4-kv9vl 1/1 Running 5 (167m ago) 45h 10.244.2.5 node02 <none> <none>
nginx-deployment-6b9d659f5f-9fxt9 1/1 Running 1 (167m ago) 3d12h 10.244.1.2 node01 <none> <none>
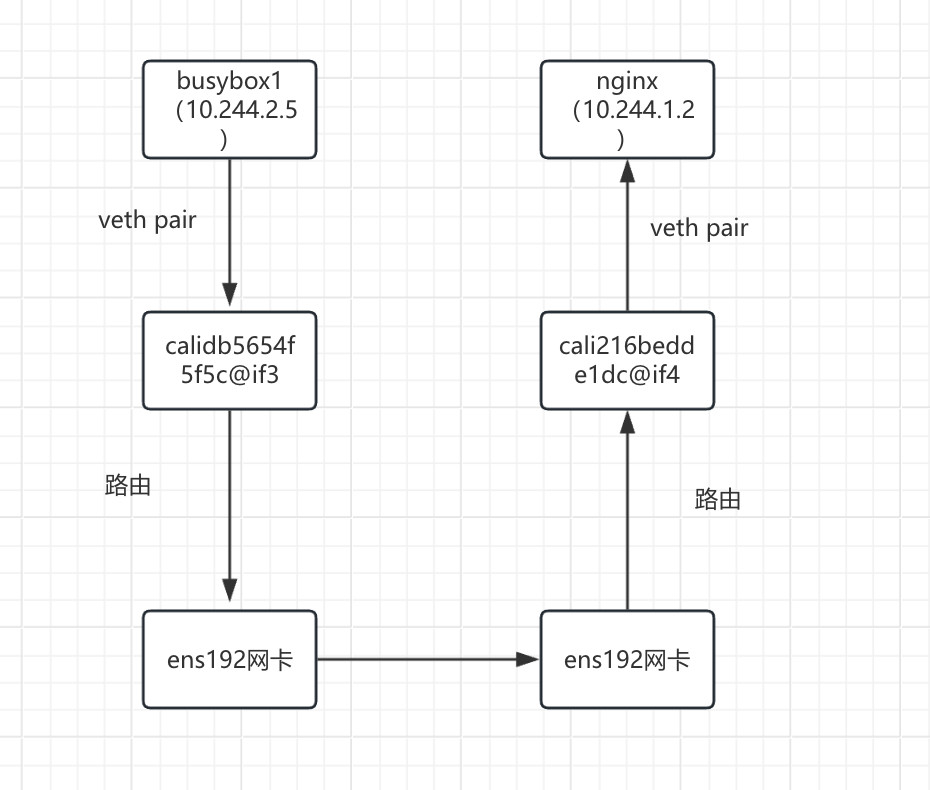
可以看到两个pod在不同的节点上,busybox1(10.244.2.5)访问nginx(10.244.1.2)
图解

实践访问流程
busybox1(10.244.2.5)发起请求,目标IP:10.244.1.2
- busybox1(10.244.2.5)容器内部进行路由决策
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- sh ip route default via 169.254.1.1 dev eth0 #目标IP为 10.244.1.2数据包将会走默认路由 169.254.1.1 dev eth0 scope link 为什么容器内的默认网关是 169.254.1.1? Calico 在默认使用 host-local IPAM 时,会配置一个虚拟的默认网关为 169.254.1.1,这不是实际存在的设备,而是 由 Calico CNI 插件在设置容器网络时写入的路由配置。数据包从 busybox1(10.244.2.5)容器内部通过veth pair 到达 Node02 的 calidb5654f5f5c@if3 接口
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- cat /sys/class/net/eth0/iflink 7 #表名接口的序号为7,然后在node02节点查看接口号 ip link show 7: calidb5654f5f5c@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 3 由此确认busybox1(10.244.2.5)容器的eth0对应的是calidb5654f5f5c@if3 接口数据包从calidb5654f5f5c@if3 接口通过路由到达tunl0网卡
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 100.100.137.200 dev tunl0 proto bird onlink 10.244.1.0/24 via 100.100.137.201 dev tunl0 proto bird onlink #目标IP为 10.244.1.2数据包将会走这条路由到tunl0网卡 blackhole 10.244.2.0/24 proto bird 10.244.2.2 dev cali14f0fd09a5c scope link 10.244.2.3 dev calie493c967aa8 scope link 10.244.2.4 dev calia8666b46cd1 scope link 10.244.2.5 dev calidb5654f5f5c scope link 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1数据包在tunl0网卡进行IPIP隧道封装
- 进行路由查询获取目标IP(10.244.1.2)对应的node IP (100.100.137.201)
查看路由: ip route |grep 10.244.1.0 10.244.1.0/24 via 100.100.137.201 dev tunl0 proto bird onlink- 封装数据包:
- 外层 IP 头: 源 IP 100.100.137.202,目标 IP 100.100.137.201。
- 内层原始包: 源IP 10.244.2.5, 目标IP 10.244.1.2 。
- 隧道设备: tunl0(MTU=1480)
- 协议:ipip-proto-4
数据包经过tunl0封装之后路由到ens192网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 100.100.137.200 dev tunl0 proto bird onlink
10.244.1.0/24 via 100.100.137.201 dev tunl0 proto bird onlink
blackhole 10.244.2.0/24 proto bird
10.244.2.2 dev cali14f0fd09a5c scope link
10.244.2.3 dev calie493c967aa8 scope link
10.244.2.4 dev calia8666b46cd1 scope link
10.244.2.5 dev calidb5654f5f5c scope link
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 #数据包经过Calico IPIP封装之后目标ip为100.100.137.1,走这条路由
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从node02的ens192网卡传输到node01的ens192网卡
- 数据包到达 node01 的ens192网卡自动送到 node01的tunl0网卡
为什么数据包会自动送到 tunl0?
IPIP 协议绑定:
tunl0 设备在内核注册为 IPIP 隧道的端点,所有协议号为 4 的 IP 包会自动递交给它。
类似 HTTP 流量交给 80 端口的服务。
数据包到达 node01tunl0网卡进行解封装
- 剥离外层封装,得到原始数据包。
- 根据目标 IP 10.244.1.2 ,通过路由将数据包交给cali216bedde1dc@if4接口 。
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 100.100.137.200 dev tunl0 proto bird onlink blackhole 10.244.1.0/24 proto bird 10.244.1.2 dev cali216bedde1dc scope link #目标IP 10.244.1.2,走这个路由 10.244.1.3 dev cali598209dffcf scope link 10.244.1.4 dev calid80d6491883 scope link 10.244.2.0/24 via 100.100.137.202 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1数据包从cali216bedde1dc@if4接口交给到nginx容器
为什么交给nginx容器?
kubectl exec -it nginx-deployment-6b9d659f5f-9fxt9 -- cat /sys/class/net/eth0/iflink
5 #表名接口的序号为5,然后在node01节点查看接口号
ip link show
5: cali216bedde1dc@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
由此确认nginx(10.244.1.2)容器的eth0对应的是cali216bedde1dc@if4 接口
抓包验证
由于在calico的默认网络模型是 IPIP,所以我们在进行数据包测试的时候,可以通过直接抓取宿主机数据包,来发现双层ip效果
busybox1容器发起请求:
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- sh
/ # ping 10.244.1.2 -c 1
PING 10.244.1.2 (10.244.1.2): 56 data bytes
64 bytes from 10.244.1.2: seq=0 ttl=62 time=2.153 ms
node01抓包:
tcpdump -i ens192 proto 4 -nn -vv
tcpdump: listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
15:21:27.581030 IP (tos 0x0, ttl 63, id 49359, offset 0, flags [DF], proto IPIP (4), length 104)
100.100.137.202 > 100.100.137.201: IP (tos 0x0, ttl 63, id 27908, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.2.5 > 10.244.1.2: ICMP echo request, id 9216, seq 0, length 64
15:21:27.581491 IP (tos 0x0, ttl 63, id 2094, offset 0, flags [none], proto IPIP (4), length 104)
100.100.137.201 > 100.100.137.202: IP (tos 0x0, ttl 63, id 44546, offset 0, flags [none], proto ICMP (1), length 84)
10.244.1.2 > 10.244.2.5: ICMP echo reply, id 9216, seq 0, length 64
BGP模型
配置calico模型为BGP模型
kubectl calico get ipPools
NAME CIDR SELECTOR
default-ipv4-ippool 10.244.0.0/16 all()
kubectl calico get ipPools default-ipv4-ippool -o yaml > default-ipv4-ippool.yaml
vim default-ipv4-ippool.yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: "2025-05-07T05:03:11Z"
name: default-ipv4-ippool
resourceVersion: "473394"
uid: 3fb4a469-fe7e-44b0-8d0a-3b8ca079633a
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 24
cidr: 10.244.0.0/16
ipipMode: CrossSubnet #将原来的Always 更换成 CrossSubnet(跨节点子网) 模式即可
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
kubectl calico apply -f default-ipv4-ippool.yaml
Successfully applied 1 'IPPool' resource(s)
环境准备
kubectl get pod -o wide
busybox1-5c99cfb6f4-kv9vl 1/1 Running 5 (167m ago) 45h 10.244.2.5 node02 <none> <none>
nginx-deployment-6b9d659f5f-9fxt9 1/1 Running 1 (167m ago) 3d12h 10.244.1.2 node01 <none> <none>
可以看到两个pod在不同的节点上,busybox1(10.244.2.5)访问nginx(10.244.1.2)
图解
实践访问流程
busybox1(10.244.2.5)发起请求,目标IP:10.244.1.2
- busybox1(10.244.2.5)容器内部进行路由决策
ip route default via 169.254.1.1 dev eth0 #目标IP为 10.244.1.2数据包将会走默认路由 169.254.1.1 dev eth0 scope link 为什么容器内的默认网关是 169.254.1.1? Calico 在默认使用 host-local IPAM 时,会配置一个虚拟的默认网关为 169.254.1.1,这不是实际存在的设备,而是 由 Calico CNI 插件在设置容器网络时写入的路由配置。数据包从 busybox1(10.244.2.5)容器内部通过veth pair 到达 Node02 的 calidb5654f5f5c@if3 接口
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- cat /sys/class/net/eth0/iflink 7 #表名接口的序号为7,然后在node02节点查看接口号 ip link show 7: calidb5654f5f5c@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 3 由此确认busybox1(10.244.2.5)容器的eth0对应的是calidb5654f5f5c@if3 接口数据包从calidb5654f5f5c@if3 接口通过路由到达ens192网卡
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 100.100.137.200 dev ens192 proto bird 10.244.1.0/24 via 100.100.137.201 dev ens192 proto bird #目标IP为 10.244.1.2数据包将会走这条路由到ens192网卡 blackhole 10.244.2.0/24 proto bird 10.244.2.2 dev cali14f0fd09a5c scope link 10.244.2.3 dev calie493c967aa8 scope link 10.244.2.4 dev calia8666b46cd1 scope link 10.244.2.5 dev calidb5654f5f5c scope link 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1数据包从node02的ens192网卡传输到node01的ens192网卡
- 数据包从node01的ens192网卡通过路由到达cali216bedde1dc@if4接口
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 100.100.137.200 dev ens192 proto bird
blackhole 10.244.1.0/24 proto bird
10.244.1.2 dev cali216bedde1dc scope link 目标IP为10.244.1.2数据包将会走这条路由。
10.244.1.3 dev cali598209dffcf scope link
10.244.1.4 dev calid80d6491883 scope link
10.244.2.0/24 via 100.100.137.202 dev ens192 proto bird
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从cali216bedde1dc@if4接口交给到nginx容器
为什么交给nginx容器?
kubectl exec -it nginx-deployment-6b9d659f5f-9fxt9 -- cat /sys/class/net/eth0/iflink
5 #表名接口的序号为5,然后在node01节点查看接口号
ip link show
5: cali216bedde1dc@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
由此确认nginx(10.244.1.2)容器的eth0对应的是cali216bedde1dc@if4 接口
抓包验证
busybox1容器发起请求:
kubectl exec -it busybox1-5c99cfb6f4-kv9vl -- sh
/ # ping 10.244.1.2 -c 1
PING 10.244.1.2 (10.244.1.2): 56 data bytes
64 bytes from 10.244.1.2: seq=0 ttl=62 time=2.153 ms
node01抓包:
tcpdump -i ens192 -nn ip host 10.244.2.5
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
15:55:41.025710 IP 10.244.2.5 > 10.244.1.2: ICMP echo request, id 14336, seq 0, length 64
15:55:41.026098 IP 10.244.1.2 > 10.244.2.5: ICMP echo reply, id 14336, seq 0, length 64
BGP模型的反射器模式实践
当前节点的网络效果
calicoctl node status
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 100.100.137.201 | node-to-node mesh | up | 05:03:38 | Established |
| 100.100.137.202 | node-to-node mesh | up | 05:03:38 | Established |
+-----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
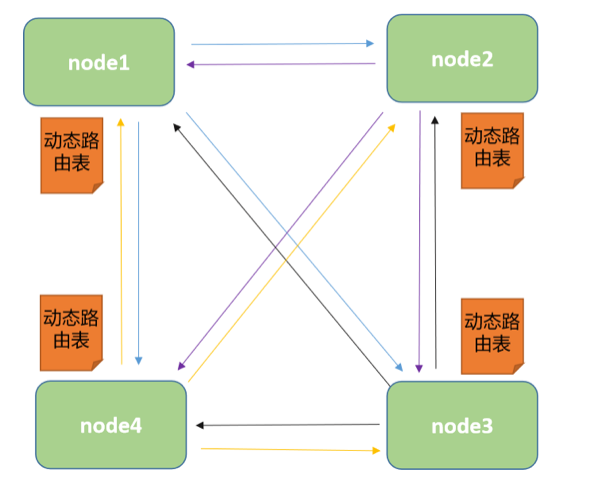
当前的calico节点的网络状态是 BGP peer 的模型效果,也就是说 每个节点上都要维护 n-1 个路由配置信息整个集群中需要维护 n*(n-1) 个路由效果,这在节点量非常多的场景中,不是我们想要的。所以我们需要实现一种 BGP reflecter 的效果。
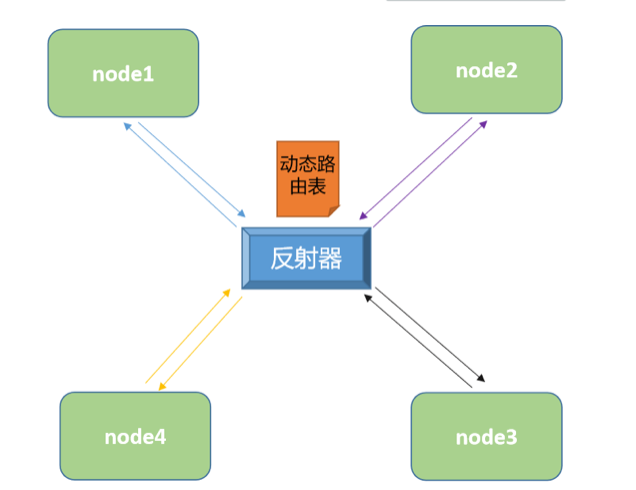
使用反射器的网络效果:
如果我们要做 BGP reflecter 效果的话,需要对反射器角色做冗余,如果我们的集群是一个多主集群的话,可以将集群的master节点作为bgp的reflecter角色,从而实现反射器的冗余。
创建反射器角色:
cat 01-calico-reflector-master.yaml
apiVersion: projectcalico.org/v3
kind: Node
metadata:
labels:
route-reflector: true
name: master01 #必须是通过 calicoctl get nodes 获取到的节点名称。
spec:
bgp:
ipv4Address: 100.100.137.200/24 #master01节点的ip地址
ipv4IPIPTunnelAddr: 10.244.0.1 #master01节点的tunl0网卡的ip地址
routeReflectorClusterID: 1.1.1.1 #是BGP网络中的唯一标识,所以这里的集群标识只要唯一就可以了
calicoctl apply -f 01-calico-reflector-master.yaml
更改节点的网络效果为 reflecter:
cat 02-calico-reflector-bgppeer.yaml
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: bgppeer-demo
spec:
nodeSelector: all() #指定所有的后端节点
peerSelector: route-reflector=="true" #指定的是反射器的标签,标识所有的后端节点与这个反射器进行数据交流
calicoctl apply -f 02-calico-reflector-bgppeer.yaml
关闭默认的网络效果:
cat 03-calico-reflector-defaultconfig.yaml
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default #在这里最好是default,因为我们要对BGP默认的网络效果进行关闭
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false #关闭后端节点的BGP peer默认状态 -- 即点对点通信关闭
asNumber: 63400 #指定的是后端节点间使用反射器的时候,我们要在一个标志号内,这里随意写一个
查看效果:
calicoctl node status
Calico process is running.
IPv4 BGP status
+-----------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+---------------+-------+----------+-------------+
| 100.100.137.201 | node specific | up | 08:36:40 | Established |
| 100.100.137.202 | node specific | up | 08:36:40 | Established |
+-----------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
默认的点对点通信方式就已经丢失了,剩下了反射器模式
其他
本章节的重点是calico底层的数据包通信流程,对于calico的策略管理(黑白名单)以及流量管控(流量限速)功能这里不做过多介绍,这两个功能生产环境一般不会使用,管理极其麻烦。之后用到我将会再做补充。。。