简介
Service对象,对于当前集群的节点来说,本质上就是工作节点的一些iptables或ipvs规则,这些规则由kube-proxy进行实时维护,站在kubernetes的发展脉络上来说,kube-proxy将请求代理至相应端点的方式有三种:userspace/iptables/ipvs。目前我们主要用的是 iptables/ipvs 两种。
模式解析
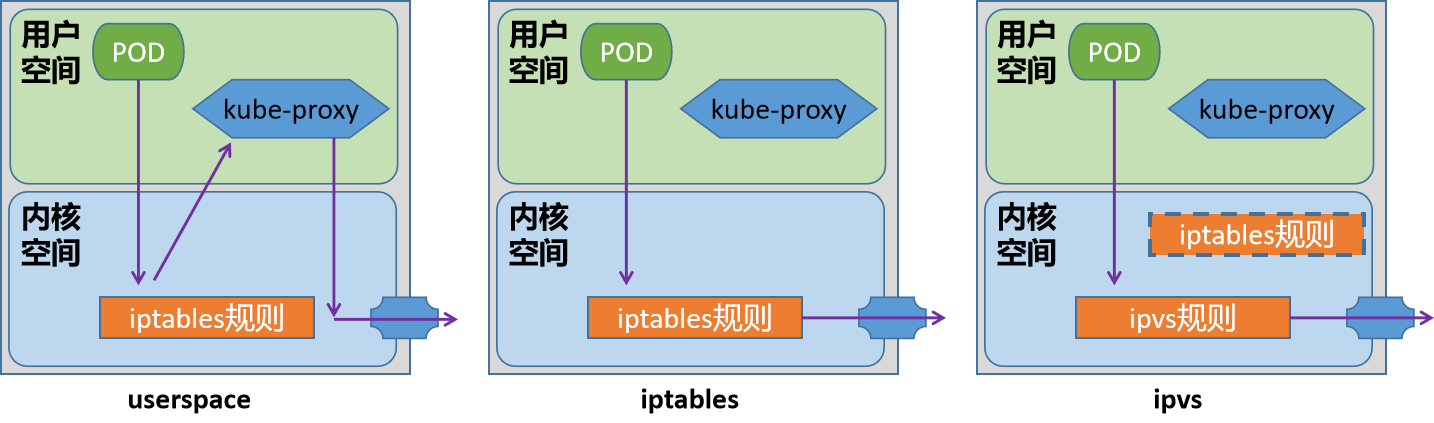
1.userspace模型是k8s(1.1-1.2)最早的一种工作模型,作用就是将service的策略转换成iptables规则,这些规则仅仅做请求的拦截,而不对请求进行调度处理。 该模型中,请求流量到达内核空间后,由套接字送往用户空间的kube-proxy,再由它送回内核空间,并调度至后端Pod。因为涉及到来回转发,效率不高,另外用户空间的转发,默认开启了会话粘滞,会导致流量转发给无效的pod上。
2.iptables模式是k8s(1.2-至今)默认的一种模式,作用是将service的策略转换成iptables规则,不仅仅包括拦截,还包括调度,捕获到达ClusterIP和Port的流量,并重定向至当前Service的代理的后端Pod资源。性能比userspace更加高效和可靠 缺点: 不会在后端Pod无响应时自动重定向,而userspace可以 中量级k8s集群(service有几百个)能够承受,但是大量级k8s集群(service有几千个)维护达几万条规则,难度较大
3.ipvs是自1.8版本引入,1.11版本起为默认设置,通过内核的Netlink接口创建相应的ipvs规则 请求流量的转发和调度功能由ipvs实现,余下的其他功能仍由iptables完成。ipvs流量转发速度快,规则同步性能好,且支持众多调度算法,如rr/lc/dh/sh/sed/nq等。
注意: 对于我们kubeadm方式安装k8s集群来说,他会首先检测当前主机上是否已经包含了ipvs模块,如果加载了,就直接用ipvs模式,如果没有加载ipvs模块的话,会自动使用iptables模式。
在k8s集群中,关于kube-proxy的所有属性信息,我们可以通过一个 configmap 的资源对象来了解一下
kubectl describe configmap kube-proxy -n kube-system
Name: kube-proxy
Namespace: kube-system
Labels: app=kube-proxy
...
iptables:
masqueradeAll: false # 这个属性打开的话,会对所有的请求都进行源地址转换
...
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: "" # 调度算法,默认是randomrobin
...
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "" # 默认没有指定,就是使用 iptables 规则
...
flannel环境
关于flannel环境我们只讲解VXLAN模型(默认)的流程,host-gw模型不经过封包解包比较简单,想了解的可以查看【flannel】章节
同一节点上的 Pod 通过 ClusterIP Service 通信流程详解
解析案例环境
kubectl get pod -o wide
busybox1-857448d9ff-shdfz 1/1 Running 0 4h44m 10.244.2.2 node02 <none> <none>
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 0 116m 10.244.2.5 node02 <none> <none>
kubectl get svc
nginx-deployment ClusterIP 10.107.254.44 <none> 80/TCP 119m
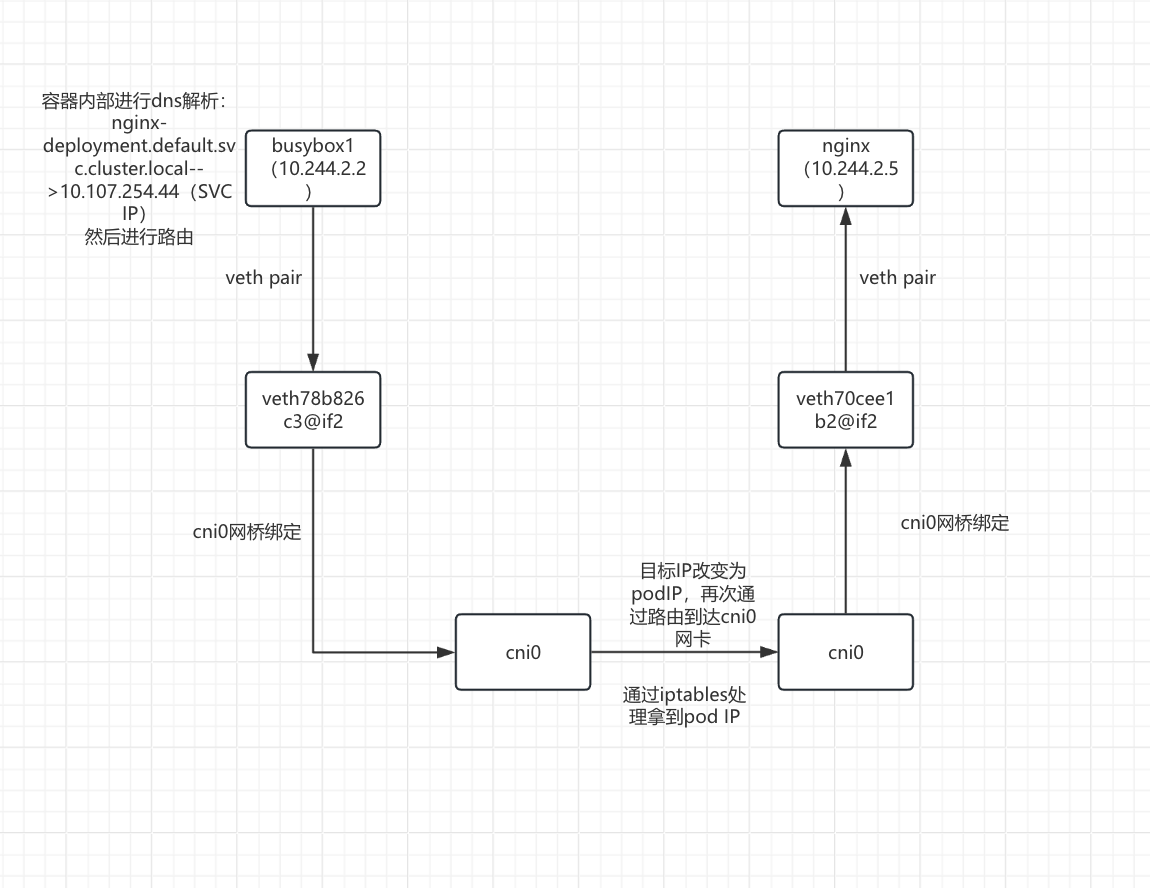
可以看到两个pod在同一节点,busybox1(10.244.2.2)访问nginx-deployment.default.svc.cluster.local
当两个pod在同一个节点时,流量转发完全在节点内部完成,无需跨节点通信。
图解
通信原理详解
- busybox1(10.244.2.2)容器内部进行dns解析:nginx-deployment.default.svc.cluster.local-->10.107.254.44(SVC IP),之后进行路由
kubectl exec -it busybox1-857448d9ff-shdfz -- sh
ip route
default via 10.244.2.1 dev eth0 # 目标IP为10.107.254.44,走默认路由,10.244.2.1 是本节点网桥 cni0 的地址
10.244.0.0/16 via 10.244.2.1 dev eth0
10.244.2.0/24 dev eth0 scope link src 10.244.2.2
- 数据包从busybox1(10.244.2.2)的eth0网卡通过veth pair虚拟网卡对到达veth78b826c3@if2接口
为什么到达veth78b826c3@if2接口?
kubectl exec -it busybox1-857448d9ff-shdfz -- cat /sys/class/net/eth0/iflink
6
在node02查看网卡接口:
ip link show
6: veth78b826c3@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether da:aa:84:90:7c:a9 brd ff:ff:ff:ff:ff:ff link-netnsid 0
数据包从veth78b826c3@if2接口通过网桥到达cni0网卡,进入iptables处理之后拿到pod IP
验证网桥绑定: brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.22bf3056c6a9 no veth70cee1b2 veth78b826c3(可以看到是和veth78b826c3@if2接口绑定的状态) veth8dcd4c25- KUBE-SERVICES链
iptables -t nat -L KUBE-SERVICES -n |grep 10.107.254.44 KUBE-SVC-UOXPL5GMPXS4446O tcp -- 0.0.0.0/0 10.107.254.44 /* default/nginx-deployment:nginx-service80 cluster IP */ tcp dpt:80 #这条规则的作用是捕获所有来源、发往 10.107.254.44:80 的 TCP 流量,并将其导向 KUBE-SVC-UOXPL5GMPXS4446O 链进行进一步处理。- KUBE-SVC-UOXPL5GMPXS4446O链
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-DBQJAEEGMK54M5LU all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议的流量,在匹配到 KUBE-SVC-UOXPL5GMPXS4446O 链的这条规则后,导向 KUBE-SEP-DBQJAEEGMK54M5LU链进行进一步处理。- KUBE-SEP-DBQJAEEGMK54M5LU 链
iptables -t nat -L KUBE-SEP-DBQJAEEGMK54M5LU -n -v 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.2.5:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.2.5:80,实现流量向特定后端 Pod 的转发这时拿到Pod IP :10.244.2.5
拿到pod IP:10.244.2.5 之后通过路由进入cni0 网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1 #目标IP:10.244.2.5 ,走这条路由到cni0网卡
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从cni0 网卡根据目标IP10.244.2.5 通过桥接到达veth70cee1b2@if2接口
验证网桥绑定:
brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.22bf3056c6a9 no veth70cee1b2(可以看到是和veth70cee1b2@if2接口绑定的状态)
veth78b826c3
veth8dcd4c25
- 数据包通过veth pair虚拟网卡对到达nginx的pod
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink
9
查看node02的网卡接口:
ip link show
9: veth70cee1b2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 96:2f:96:06:80:ec brd ff:ff:ff:ff:ff:ff link-netnsid 2
不同节点上的 Pod 通过 ClusterIP Service 通信流程详解
解析案例环境
kubectl get pod -o wide
busybox3-c997b9cc4-tlvrq 1/1 Running 0 4h25m 10.244.1.2 node01 <none> <none>
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 0 3h10m 10.244.2.5 node02 <none> <none>
kubectl get svc
nginx-deployment ClusterIP 10.107.254.44 <none> 80/TCP 3h9m
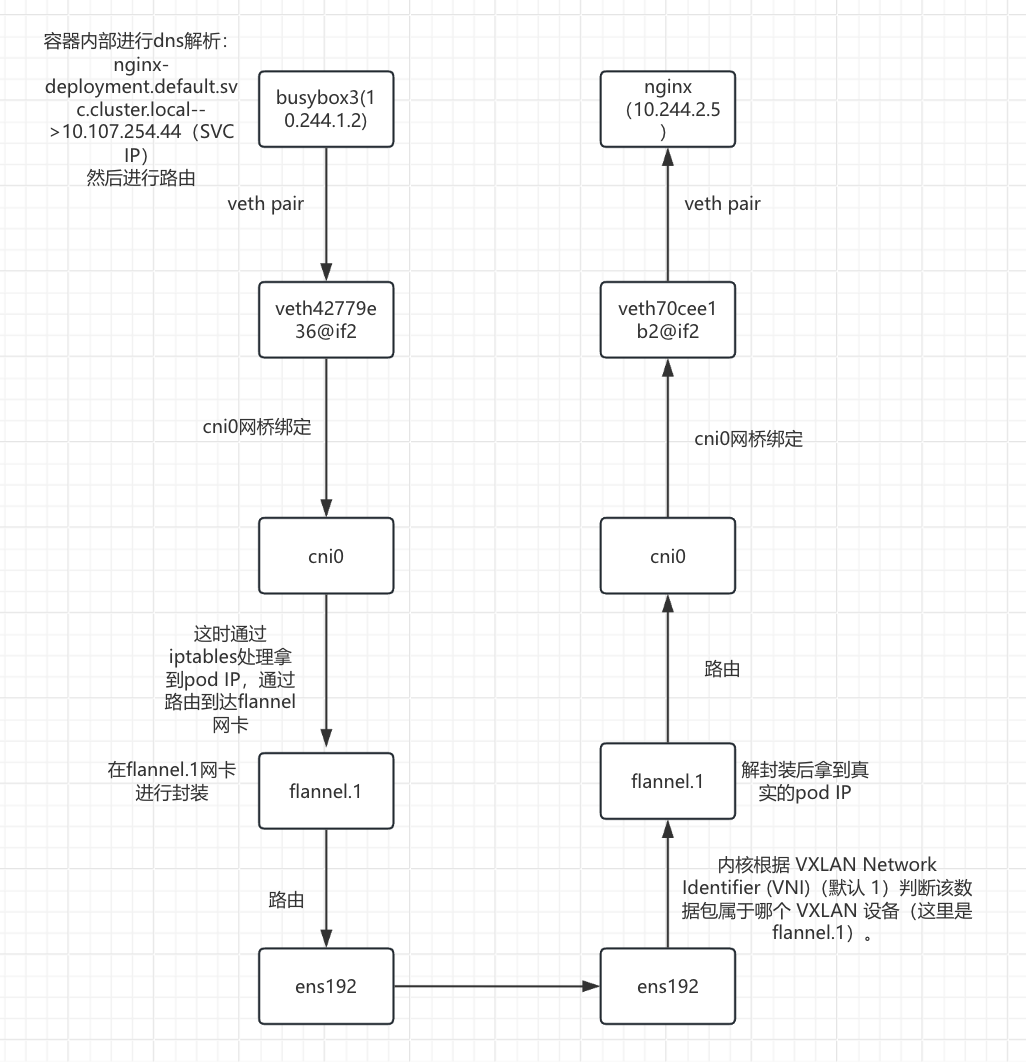
可以看到两个pod存在不同节点,busybox3(10.244.1.2)通过svc的域名(nginx-deployment.default.svc.cluster.local)访问nginx
图解
通信原理详解
- busybox3(10.244.1.2)容器内部解析:nginx-deployment.default.svc.cluster.local-->10.107.254.44,之后进行路由
kubectl exec -it busybox3-c997b9cc4-tlvrq -- sh
ip route
default via 10.244.1.1 dev eth0 # 目标IP为10.107.254.44,走默认路由,10.244.1.1 是本节点网桥 cni0 的地址
10.244.0.0/16 via 10.244.1.1 dev eth0
10.244.1.0/24 dev eth0 scope link src 10.244.1.2
- 数据包从busybox3(10.244.1.2)的eth0网卡通过veth pair虚拟网卡对到达veth42779e36@if2接口
为什么到达veth42779e36@if2接口?
kubectl exec -it busybox3-c997b9cc4-tlvrq -- cat /sys/class/net/eth0/iflink
6
在node01查看网卡接口:
ip link show
6: veth42779e36@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 26:a9:23:fb:7a:c7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
数据包从veth42779e36@if2接口通过网桥到达cni0网卡,进入iptables处理之后拿到pod IP
验证是真的通过网桥? brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.1a70cf92258b no veth19ff212d veth42779e36 (可以cni0网卡看到是和veth42779e36@if2接口绑定的状态)- KUBE-SERVICES链
iptables -t nat -L KUBE-SERVICES -n |grep 10.107.254.44 KUBE-SVC-UOXPL5GMPXS4446O tcp -- 0.0.0.0/0 10.107.254.44 /* default/nginx-deployment:nginx-service80 cluster IP */ tcp dpt:80 #这条规则的作用是捕获所有来源、发往 10.107.254.44:80 的 TCP 流量,并将其导向 KUBE-SVC-UOXPL5GMPXS4446O 链进行进一步处理。- KUBE-SVC-UOXPL5GMPXS4446O链
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-DBQJAEEGMK54M5LU all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议的流量,在匹配到 KUBE-SVC-UOXPL5GMPXS4446O 链的这条规则后,导向 KUBE-SEP-DBQJAEEGMK54M5LU链进行进一步处理。 若 Service 有多个后端 Pod,KUBE-SVC 链会使用 iptables 的 statistic 模块进行随机负载均衡。- KUBE-SEP-DBQJAEEGMK54M5LU 链
iptables -t nat -L KUBE-SEP-DBQJAEEGMK54M5LU -n -v 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.2.5:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.2.5:80,实现流量向特定后端 Pod 的转发
这时拿到Pod IP :10.244.2.5
拿到Pod IP之后通过路由到达flannel网卡进行封装
查看路由: ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink #目标IP为10.244.2.5,走这条路由到达flannel.1网卡 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- FDB 表查询: node01 查询 FDB 表,获取目标 VTEP(
10.244.2.0/24)对应的物理 IP(100.100.137.202)和 MAC 地址:
bridge fdb show dev flannel.1 de:65:a0:34:f0:d6 dst 100.100.137.200 self permanent ae:f9:fd:4f:2a:16 dst 100.100.137.202 self permanent #根据flannel为每个node分配的子网和目标ip进行匹配,找到 10.244.2.0/24 对应的条目是这条- 封装 VXLAN 数据包:
- 外层 IP 头:源 IP 100.100.137.201,目标 IP 100.100.137.202。
- 外层 UDP 头:源端口随机,目标端口 8472(Flannel 默认 VXLAN 端口)。
- VXLAN 头:VNI(VXLAN Network Identifier)为
1。 - 原始数据包:源 IP 10.244.1.2 ,目标 IP 10.244.2.5。
- FDB 表查询: node01 查询 FDB 表,获取目标 VTEP(
数据包经过flannel封装之后路由到ens192网卡
查看路由:
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 #数据包经过flannel封装之后目标ip为100.100.137.202,走这条路由
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
数据包从node01的ens192网卡传输到node02的ens192网卡
数据包到达 node02 的ens192网卡进行识别
内核根据 VXLAN Network Identifier (VNI)(默认 1)判断该数据包属于哪个 VXLAN 设备(这里是 flannel.1)。
数据包到达 node02 flannel的网卡进行VXLAN解封装
Node02 的 flannel.1 接口监听 UDP 端口 8472,接收数据包后:
- 验证 VNI 是否匹配(1)。
- 剥离外层 IP、UDP 和 VXLAN 头,得到原始数据包。
- 根据目标 IP 10.244.2.5 ,通过路由将数据包交给 cni0 网桥。
查看路由: ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1 #解封装之后真实目标IP地址为10.244.2.5,走此条路由 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
数据包从cni0 网卡根据目标IP10.244.2.5 通过桥接到达veth70cee1b2@if2接口
验证网桥绑定:
brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.22bf3056c6a9 no veth70cee1b2(可以看到是和veth70cee1b2@if2接口绑定的状态)
veth78b826c3
veth8dcd4c25
- 数据包通过veth pair虚拟网卡对到达nginx的pod
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink
9
查看node02的网卡接口:
ip link show
9: veth70cee1b2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 96:2f:96:06:80:ec brd ff:ff:ff:ff:ff:ff link-netnsid 2
访问NodePort Service通信流程详解
解析案例环境
kubectl get pod -o wide
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 0 5h1m 10.244.2.5 node02 <none> <none>
kubectl get svc
nginx-deployment NodePort 10.107.254.44 <none> 80:31856/TCP 4h59m
访问nodeIP:31856
图解
通信原理详解
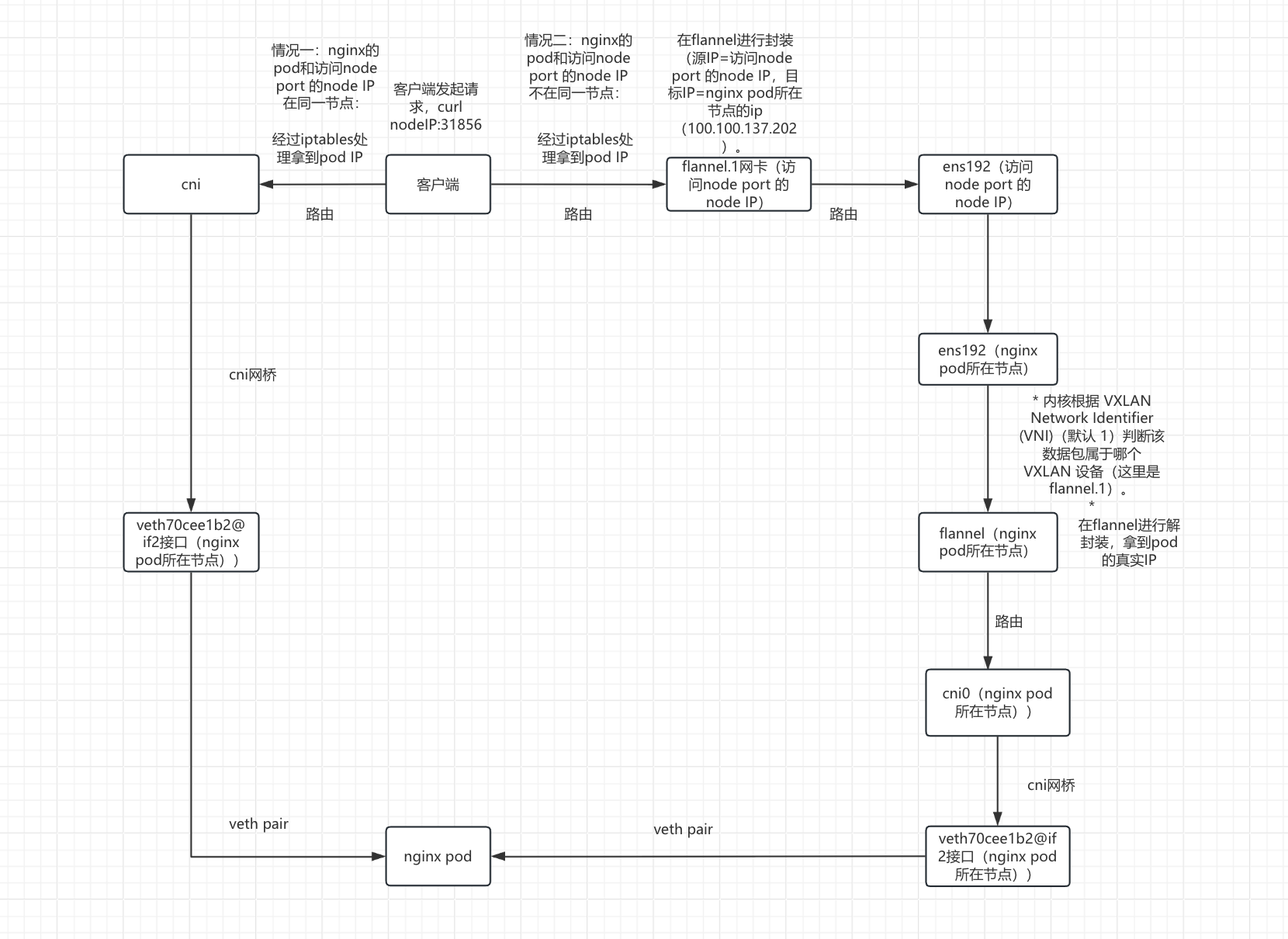
客户端发起请求,curl nodeIP:31856
进入iptables处理之后拿到pod IP
- KUBE-NODEPORTS链匹配NodePort
iptables -t nat -L KUBE-NODEPORTS -n -v 0 0 KUBE-SVC-UOXPL5GMPXS4446O tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp dpt:31856 这条规则的作用是将所有来源、所有目标的 TCP 流量,当目标端口为 31856 时,导向 KUBE-SVC-UOXPL5GMPXS4446O链进行进一步处理- KUBE-SVC-UOXPL5GMPXS4446O链进行负载均衡
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-DBQJAEEGMK54M5LU all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议,从任意网络接口进出的流量,在匹配到该规则后,导向 KUBE-SEP-DBQJAEEGMK54M5LU 链进行进一步处理- KUBE-SEP-DBQJAEEGMK54M5LU链执行DNAT
iptables -t nat -L KUBE-SEP-DBQJAEEGMK54M5LU -n -v Chain KUBE-SEP-DBQJAEEGMK54M5LU (1 references) pkts bytes target prot opt in out source destination 0 0 KUBE-MARK-MASQ all -- * * 10.244.2.5 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.2.5:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.2.5:80,实现流量向特定后端 Pod 的转发这时拿到pod IP:10.244.2.5
这时分为两种情况,但最终的目的都是数据包到达nginx 的pod(10.244.2.5)
!!!情况一:nginx的pod和访问node port 的node IP在同一节点:
- 数据包直接通过路由到达cni0网卡
查看路由: ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1 #目标IP 为10.244.2.5,走这条路由 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 数据包根据目标IP通过网桥到达veth70cee1b2@if2接口
验证网桥关系: brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.22bf3056c6a9 no veth70cee1b2 (可以看到确实是网桥绑定关系) veth78b826c3 veth8dcd4c25- 数据包从veth70cee1b2@if2接口通过veth pair 到达nginx 容器
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink 9 ip link show 9: veth70cee1b2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default link/ether 96:2f:96:06:80:ec brd ff:ff:ff:ff:ff:ff link-netnsid 2
!!!情况二:nginx的pod和访问node port 的node IP不在同一节点:
数据包通过路由到达flannel.1网卡(访问node port 的node IP)进行封装
查看路由: ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink 10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink #目标IP 为10.244.2.5,走这条路由到达flannel.1网卡 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 封装VXLAN包:
- 外层IP头:源IP=访问node port 的node IP,目标IP=nginx pod所在节点的ip(100.100.137.202)。
- 外层 UDP 头:源端口随机,目标端口 8472(Flannel 默认 VXLAN 端口)。
- VXLAN 头:VNI(VXLAN Network Identifier)为
1。 - 原始数据包:目标 IP 10.244.2.5。
- 封装VXLAN包:
数据包从flannel.1网卡(访问node port 的node IP)通过路由到达ens192网卡(访问node port 的node IP)
route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 100.100.137.1 0.0.0.0 UG 100 0 0 ens192 10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1 100.100.137.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192 #经过封装之后目标IP为100.100.137.202,走这条路由 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0数据包通过ens192网卡(访问node port 的node IP)传输到ens192网卡(100.100.137.202/nginx pod所在的节点)
数据包到达ens192网卡(100.100.137.202/nginx pod所在的节点)进行识别之后发送到flannel网卡(100.100.137.202/nginx pod所在的节点)
内核根据 VXLAN Network Identifier (VNI)(默认 1)判断该数据包属于哪个 VXLAN 设备(这里是 flannel.1)。
数据包到达flannel网卡(100.100.137.202/nginx pod所在的节点)之后进行解封装
- flannel.1 接口监听 UDP 端口 8472,接收数据包后:
- 验证 VNI 是否匹配(1)。
- 剥离外层 IP、UDP 和 VXLAN 头,得到原始数据包。
- 原始目标 IP:10.244.2.5
- flannel.1 接口监听 UDP 端口 8472,接收数据包后:
数据包通过路由到达cni0网卡
route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 100.100.137.1 0.0.0.0 UG 100 0 0 ens192 10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1 10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1 10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 #解封装之后目标IP:10.244.2.5 ,走这条路由 100.100.137.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0- 数据包根据目标IP通过网桥到达veth70cee1b2@if2接口
验证网桥关系: brctl show cni0 bridge name bridge id STP enabled interfaces cni0 8000.22bf3056c6a9 no veth70cee1b2 (可以看到确实是网桥绑定关系) veth78b826c3 veth8dcd4c25- 数据包从veth70cee1b2@if2接口通过veth pair 到达nginx 容器
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink 9 ip link show 9: veth70cee1b2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default link/ether 96:2f:96:06:80:ec brd ff:ff:ff:ff:ff:ff link-netnsid 2
calico环境
关于flannel环境我们只讲解IPIP模型(默认)的流程,其他模型可以查看【calico章节】
同一节点上的 Pod 通过 ClusterIP Service 通信流程详解
解析案例环境
kubectl get pod -o wide
busybox1-857448d9ff-shdfz 1/1 Running 1 (3d1h ago) 4d1h 10.244.140.65 node02 <none> <none>
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 1 (3d1h ago) 3d22h 10.244.140.66 node02 <none> <none>
kubectl get svc
nginx-deployment ClusterIP 10.107.254.44 <none> 80/TCP 3d22h
可以看到两个pod在同一节点,busybox1(10.244.140.65)访问nginx-deployment.default.svc.cluster.local
图解
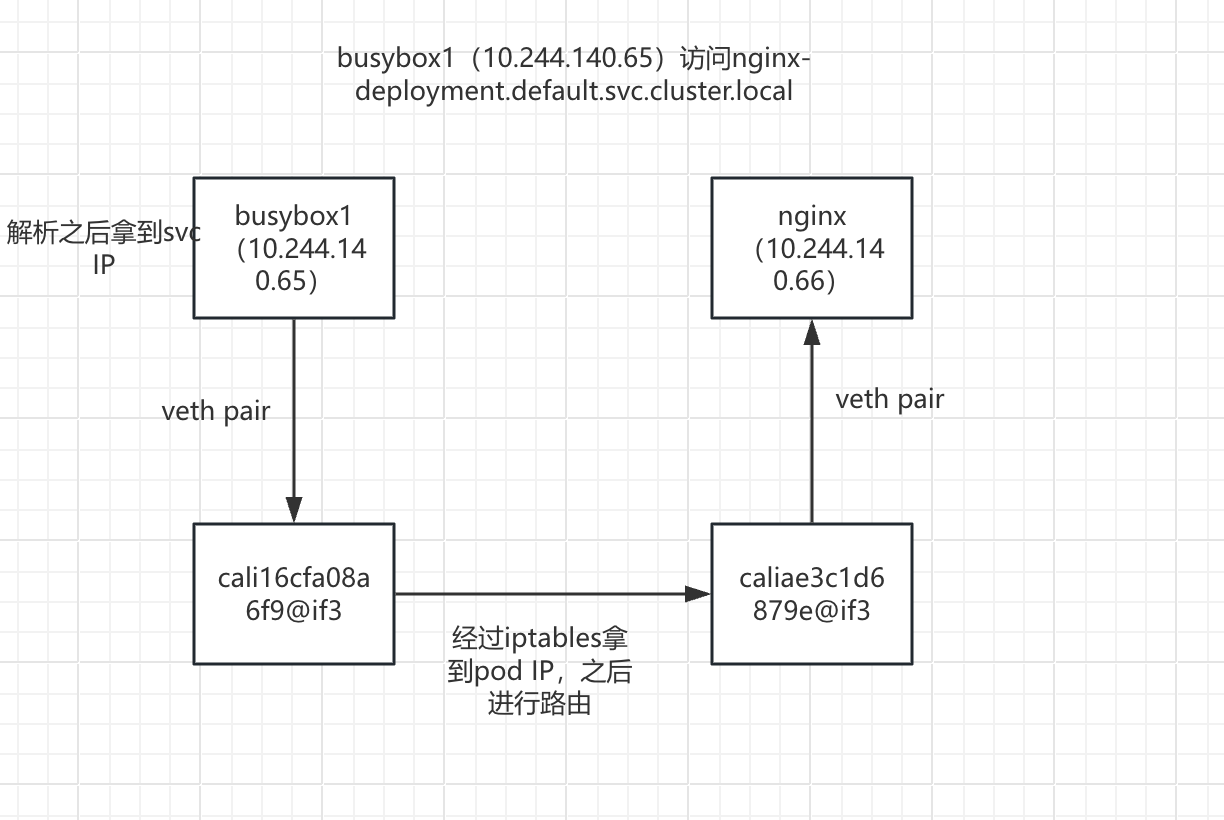
通信原理详解
- busybox1(10.244.140.65)容器内部进行dns解析:nginx-deployment.default.svc.cluster.local-->10.107.254.44(SVC IP),之后进行路由
kubectl exec -it busybox1-857448d9ff-shdfz -- sh
ip route
default via 169.254.1.1 dev eth0 #目标IP为10.107.254.44,走默认路由
169.254.1.1 dev eth0 scope link
为什么容器内的默认网关是 169.254.1.1?
Calico 会配置一个虚拟的默认网关为 169.254.1.1,这不是实际存在的设备,而是 由 Calico CNI 插件在设置容器网络时写入的路由配置。
- 数据包从busybox1(10.244.140.65)的eth0网卡通过veth pair虚拟网卡对到达cali16cfa08a6f9@if3接口
为什么到达veth78b826c3@if2接口?
kubectl exec -it busybox1-857448d9ff-shdfz -- cat /sys/class/net/eth0/iflink
4
在node02查看网卡接口:
ip link show
4: cali16cfa08a6f9@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
数据包进入iptables处理
- KUBE-SERVICES链
iptables -t nat -L KUBE-SERVICES -n |grep 10.107.254.44 KUBE-SVC-UOXPL5GMPXS4446O tcp -- 0.0.0.0/0 10.107.254.44 /* default/nginx-deployment:nginx-service80 cluster IP */ tcp dpt:80 #这条规则的作用是捕获所有来源、发往 10.107.254.44:80 的 TCP 流量,并将其导向 KUBE-SVC-UOXPL5GMPXS4446O 链进行进一步处理。- KUBE-SVC-UOXPL5GMPXS4446O链:Service 的负载均衡链(如果有多个 Endpoint 会做 DNAT 轮询)。
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-FALJWON3ZI76YI6S all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议的流量,在匹配到 KUBE-SVC-UOXPL5GMPXS4446O 链的这条规则后,导向 KUBE-SEP-FALJWON3ZI76YI6S链进行进一步处理。- KUBE-SEP-FALJWON3ZI76YI6S链
iptables -t nat -L KUBE-SEP-FALJWON3ZI76YI6S -n -v 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.140.66:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.140.66:80,实现流量向特定后端 Pod 的转发这时拿到Pod IP :10.244.140.66
拿到pod IP:10.244.140.66 之后通过路由进入 caliae3c1d6879e@if3网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
blackhole 10.244.140.64/26 proto bird
10.244.140.65 dev cali16cfa08a6f9 scope link
10.244.140.66 dev caliae3c1d6879e scope link # 目标IP:10.244.140.66,走这条路由
10.244.140.67 dev calibc123ec5773 scope link
10.244.140.69 dev cali20636a2ec93 scope link
10.244.196.128/26 via 100.100.137.201 dev tunl0 proto bird onlink
10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从caliae3c1d6879e@if3接口通过veth pair到nginx pod
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink
5
5: caliae3c1d6879e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1
不同节点上的 Pod 通过 ClusterIP Service 通信流程详解
解析案例环境
kubectl get pod -o wide
busybox3-c997b9cc4-tlvrq 1/1 Running 1 (3d2h ago) 4d 10.244.196.131 node01 <none> <none>
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 1 (3d2h ago) 3d23h 10.244.140.66 node02 <none> <none>
kubectl get svc
nginx-deployment ClusterIP 10.107.254.44 <none> 80/TCP 3d22h
可以看到两个pod在不同节点,busybox3(10.244.196.131)通过svc的域名(nginx-deployment.default.svc.cluster.local)访问nginx
图解
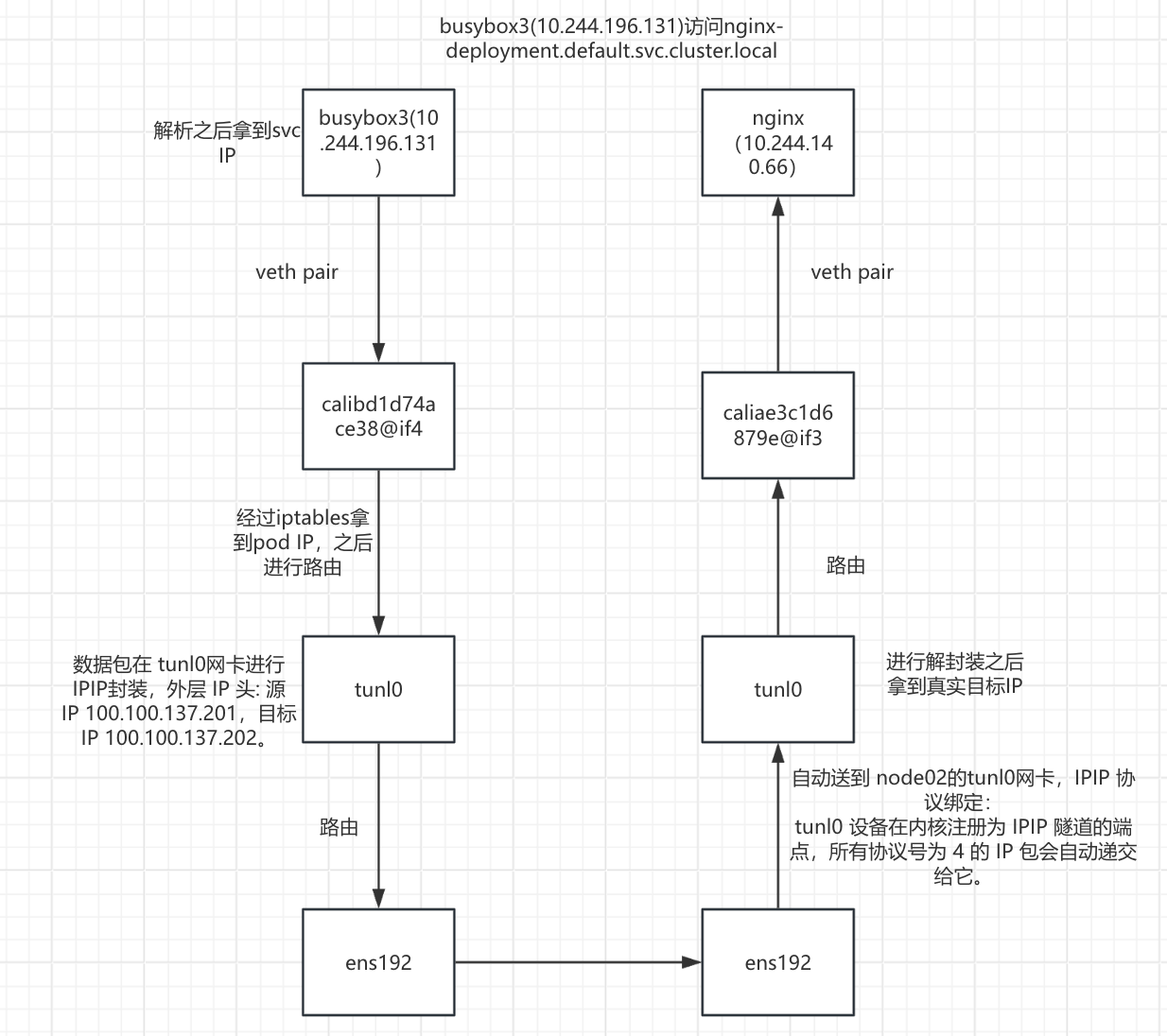
通信原理详解
- busybox3(10.244.196.131)容器内部解析:nginx-deployment.default.svc.cluster.local-->10.107.254.44,之后进行路由
kubectl exec -it busybox3-c997b9cc4-tlvrq -- sh
ip route
default via 169.254.1.1 dev eth0 #目标IP为10.107.254.44,走默认路由
169.254.1.1 dev eth0 scope link
为什么容器内的默认网关是 169.254.1.1?
Calico 会配置一个虚拟的默认网关为 169.254.1.1,这不是实际存在的设备,而是 由 Calico CNI 插件在设置容器网络时写入的路由配置。
- 数据包从busybox3(10.244.196.131)的eth0网卡通过veth pair虚拟网卡对到达calibd1d74ace38@if4接口
为什么到达calibd1d74ace38@if4接口?
kubectl exec -it busybox3-c997b9cc4-tlvrq -- cat /sys/class/net/eth0/iflink
7
在node01查看网卡接口:
ip link show
7: calibd1d74ace38@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2
数据包进入iptables处理
- KUBE-SERVICES链
iptables -t nat -L KUBE-SERVICES -n |grep 10.107.254.44 KUBE-SVC-UOXPL5GMPXS4446O tcp -- 0.0.0.0/0 10.107.254.44 /* default/nginx-deployment:nginx-service80 cluster IP */ tcp dpt:80 #这条规则的作用是捕获所有来源、发往 10.107.254.44:80 的 TCP 流量,并将其导向 KUBE-SVC-UOXPL5GMPXS4446O 链进行进一步处理。- KUBE-SVC-UOXPL5GMPXS4446O链:Service 的负载均衡链(如果有多个 Endpoint 会做 DNAT 轮询)。
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-FALJWON3ZI76YI6S all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议的流量,在匹配到 KUBE-SVC-UOXPL5GMPXS4446O 链的这条规则后,导向 KUBE-SEP-FALJWON3ZI76YI6S链进行进一步处理。- KUBE-SEP-FALJWON3ZI76YI6S链
iptables -t nat -L KUBE-SEP-FALJWON3ZI76YI6S -n -v 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.140.66:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.140.66:80,实现流量向特定后端 Pod 的转发
这时拿到Pod IP :10.244.140.66
- 拿到pod IP:10.244.140.66 之后通过路由进入 tunl0网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink #目标IP为10.244.140.66,走这条路由到达tunl0网卡
blackhole 10.244.196.128/26 proto bird
10.244.196.129 dev cali48e9a291abc scope link
10.244.196.130 dev calif738bc18da9 scope link
10.244.196.131 dev calibd1d74ace38 scope link
10.244.196.133 dev cali19568210fca scope link
10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
数据包在 tunl0网卡进行IPIP封装
- 进行路由查询获取目标IP(10.244.140.66)对应的node IP (100.100.137.202)
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink #目标IP为10.244.140.66,走这条路由,可以看到网关为:100.100.137.202 blackhole 10.244.196.128/26 proto bird 10.244.196.129 dev cali48e9a291abc scope link 10.244.196.130 dev calif738bc18da9 scope link 10.244.196.131 dev calibd1d74ace38 scope link 10.244.196.133 dev cali19568210fca scope link 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 封装数据包:
- 外层 IP 头: 源 IP 100.100.137.201,目标 IP 100.100.137.202。
- 内层原始包: 源IP 10.244.196.131, 目标IP 10.244.140.66。
- 隧道设备: tunl0(MTU=1480)
- 协议:ipip-proto-4
数据包经过tunl0封装之后路由到ens192网卡
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink
blackhole 10.244.196.128/26 proto bird
10.244.196.129 dev cali48e9a291abc scope link
10.244.196.130 dev calif738bc18da9 scope link
10.244.196.131 dev calibd1d74ace38 scope link
10.244.196.133 dev cali19568210fca scope link
10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 #数据包封装之后目标ip为100.100.137.202,走这条路由
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从node01的ens192网卡传输到node02的ens192网卡
- 数据包到达 node02 的ens192网卡自动送到 node02的tunl0网卡
为什么数据包会自动送到 tunl0?
IPIP 协议绑定:
tunl0 设备在内核注册为 IPIP 隧道的端点,所有协议号为 4 的 IP 包会自动递交给它。
类似 HTTP 流量交给 80 端口的服务。
- 数据包到达 node02 tunl0网卡进行解封装之后通过路由到达 caliae3c1d6879e@if3接口
ip route
default via 100.100.137.1 dev ens192 proto static metric 100
blackhole 10.244.140.64/26 proto bird
10.244.140.65 dev cali16cfa08a6f9 scope link
10.244.140.66 dev caliae3c1d6879e scope link #解封装之后真实IP为:10.244.140.66,走这条路由
10.244.140.67 dev calibc123ec5773 scope link
10.244.140.69 dev cali20636a2ec93 scope link
10.244.196.128/26 via 100.100.137.201 dev tunl0 proto bird onlink
10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink
100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
- 数据包从 caliae3c1d6879e@if3接口通过veth pair交给到nginx容器
为什么交给nginx容器?
kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink
5
5: caliae3c1d6879e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1
访问NodePort Service通信流程详解
解析案例环境
kubectl get pod -o wide
nginx-deployment-6b9d659f5f-qbchs 1/1 Running 1 (3d3h ago) 4d 10.244.140.66 node02 <none> <none>
kubectl get svc
nginx-deployment NodePort 10.107.254.44 <none> 80:30008/TCP 4d
访问nodeIP:30008
图解
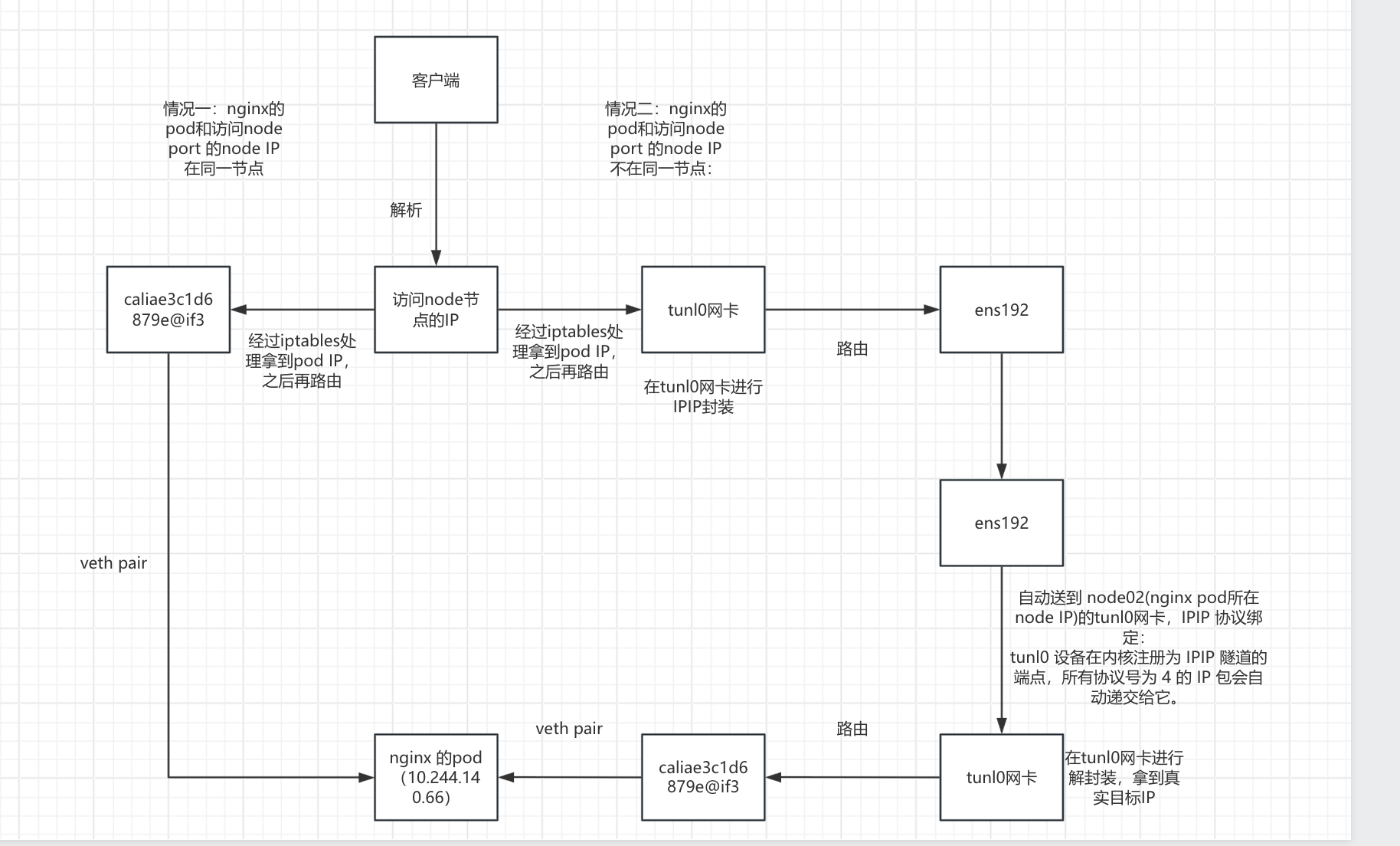
通信原理详解
客户端发起请求,curl nodeIP:30008
进入iptables处理之后拿到pod IP
- KUBE-NODEPORTS链匹配NodePort
iptables -t nat -L KUBE-NODEPORTS -n -v 0 0 KUBE-SVC-UOXPL5GMPXS4446O tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp dpt:30008 这条规则的作用是将所有来源、所有目标的 TCP 流量,当目标端口为 30008 时,导向 KUBE-SVC-UOXPL5GMPXS4446O链进行进一步处理- KUBE-SVC-UOXPL5GMPXS4446O链进行负载均衡
iptables -t nat -L KUBE-SVC-UOXPL5GMPXS4446O -n -v 0 0 KUBE-SEP-FALJWON3ZI76YI6S all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ 这条规则的作用是将所有来源、所有目标、所有协议,从任意网络接口进出的流量,在匹配到该规则后,导向 KUBE-SEP-FALJWON3ZI76YI6S 链进行进一步处理- KUBE-SEP-FALJWON3ZI76YI6S链执行DNAT
iptables -t nat -L KUBE-SEP-FALJWON3ZI76YI6S -n -v 0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/nginx-deployment:nginx-service80 */ tcp to:10.244.140.66:80 这条规则的作用是将任何来源和目标的 TCP 流量的目标地址和端口转换为 10.244.140.66:80,实现流量向特定后端 Pod 的转发
这时拿到pod IP:10.244.140.66
这时分为两种情况,但最终的目的都是数据包到达nginx 的pod(10.244.140.66)
!!!情况一:nginx的pod和访问node port 的node IP在同一节点:
- 数据包直接通过路由到达caliae3c1d6879e@if3接口
ip route default via 100.100.137.1 dev ens192 proto static metric 100 blackhole 10.244.140.64/26 proto bird 10.244.140.65 dev cali16cfa08a6f9 scope link 10.244.140.66 dev caliae3c1d6879e scope link #目标IP为:10.244.140.66,走这条路由 10.244.140.67 dev calibc123ec5773 scope link 10.244.140.69 dev cali20636a2ec93 scope link 10.244.196.128/26 via 100.100.137.201 dev tunl0 proto bird onlink 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 数据包从 caliae3c1d6879e@if3接口通过veth pair交给到nginx容器
为什么交给nginx容器? kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink 5 5: caliae3c1d6879e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1!!!情况二:nginx的pod和访问node port 的node IP不在同一节点:
- 通过路由进入 tunl0网卡(访问node port 的node )
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink #目标IP为10.244.140.66,走这条路由到达tunl0网卡 blackhole 10.244.196.128/26 proto bird 10.244.196.129 dev cali48e9a291abc scope link 10.244.196.130 dev calif738bc18da9 scope link 10.244.196.131 dev calibd1d74ace38 scope link 10.244.196.133 dev cali19568210fca scope link 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1数据包在 tunl0网卡(访问node port 的node )进行IPIP封装
- 进行路由查询获取目标IP(10.244.140.66)对应的node IP (100.100.137.202)
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink #目标IP为10.244.140.66,走这条路由,可以看到网关为:100.100.137.202 blackhole 10.244.196.128/26 proto bird 10.244.196.129 dev cali48e9a291abc scope link 10.244.196.130 dev calif738bc18da9 scope link 10.244.196.131 dev calibd1d74ace38 scope link 10.244.196.133 dev cali19568210fca scope link 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 封装数据包:
- 外层 IP 头: 源 IP (访问node port 的node IP),目标 IP 100.100.137.202(nginx pod所在node IP)。
- 内层原始包: 目标IP 10.244.140.66。
- 隧道设备: tunl0(MTU=1480)
- 协议:ipip-proto-4
数据包经过tunl0(访问node port 的node)封装之后路由到ens192网卡(访问node port 的node)
ip route default via 100.100.137.1 dev ens192 proto static metric 100 10.244.140.64/26 via 100.100.137.202 dev tunl0 proto bird onlink blackhole 10.244.196.128/26 proto bird 10.244.196.129 dev cali48e9a291abc scope link 10.244.196.130 dev calif738bc18da9 scope link 10.244.196.131 dev calibd1d74ace38 scope link 10.244.196.133 dev cali19568210fca scope link 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.201 metric 100 #数据包封装之后目标ip为100.100.137.202,走这条路由 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 数据包从ens192网卡(访问node port 的node)传输到node02(nginx pod所在node IP)的ens192网卡
- 数据包到达 node02(nginx pod所在node IP) 的ens192网卡自动送到 node02(nginx pod所在node IP)的tunl0网卡
为什么数据包会自动送到 tunl0? IPIP 协议绑定: tunl0 设备在内核注册为 IPIP 隧道的端点,所有协议号为 4 的 IP 包会自动递交给它。 类似 HTTP 流量交给 80 端口的服务。- 数据包到达 node02(nginx pod所在node IP)的 tunl0网卡进行解封装之后通过路由到达 caliae3c1d6879e@if3接口
ip route default via 100.100.137.1 dev ens192 proto static metric 100 blackhole 10.244.140.64/26 proto bird 10.244.140.65 dev cali16cfa08a6f9 scope link 10.244.140.66 dev caliae3c1d6879e scope link #解封装之后真实IP为:10.244.140.66,走这条路由 10.244.140.67 dev calibc123ec5773 scope link 10.244.140.69 dev cali20636a2ec93 scope link 10.244.196.128/26 via 100.100.137.201 dev tunl0 proto bird onlink 10.244.241.64/26 via 100.100.137.200 dev tunl0 proto bird onlink 100.100.137.0/24 dev ens192 proto kernel scope link src 100.100.137.202 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1- 数据包从 caliae3c1d6879e@if3接口通过veth pair交给到nginx容器
为什么交给nginx容器? kubectl exec -it nginx-deployment-6b9d659f5f-qbchs -- cat /sys/class/net/eth0/iflink 5 5: caliae3c1d6879e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1