概述
就目前Docker自身默认的网络来说,单台主机上的不同Docker容器可以借助docker0网桥直接通信,这没毛病
而不同主机上的Docker容器之间只能通过在主机上用映射端口的方法来进行通信,有时这种方式会很不方便,甚至达不到我们的要求。宿主机端口不够了,冲突了怎么办?
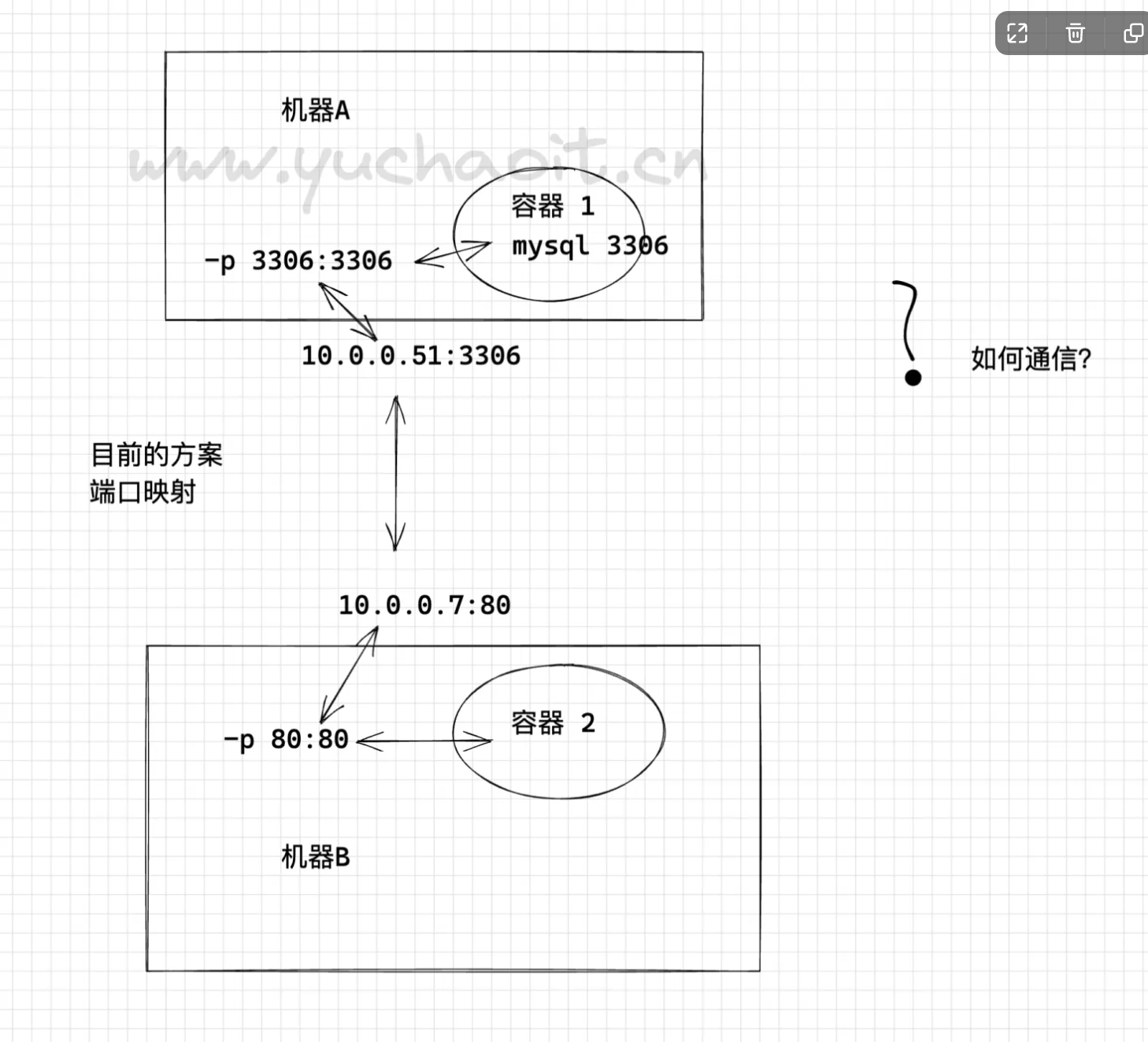
因此位于不同物理机上的Docker容器之间直接使用本身的IP地址进行通信很有必要。
再者说,如果将Docker容器起在不同的物理主机上,我们不可避免的会遭遇到Docker容器的跨主机通信问题。本文就来尝试一下。
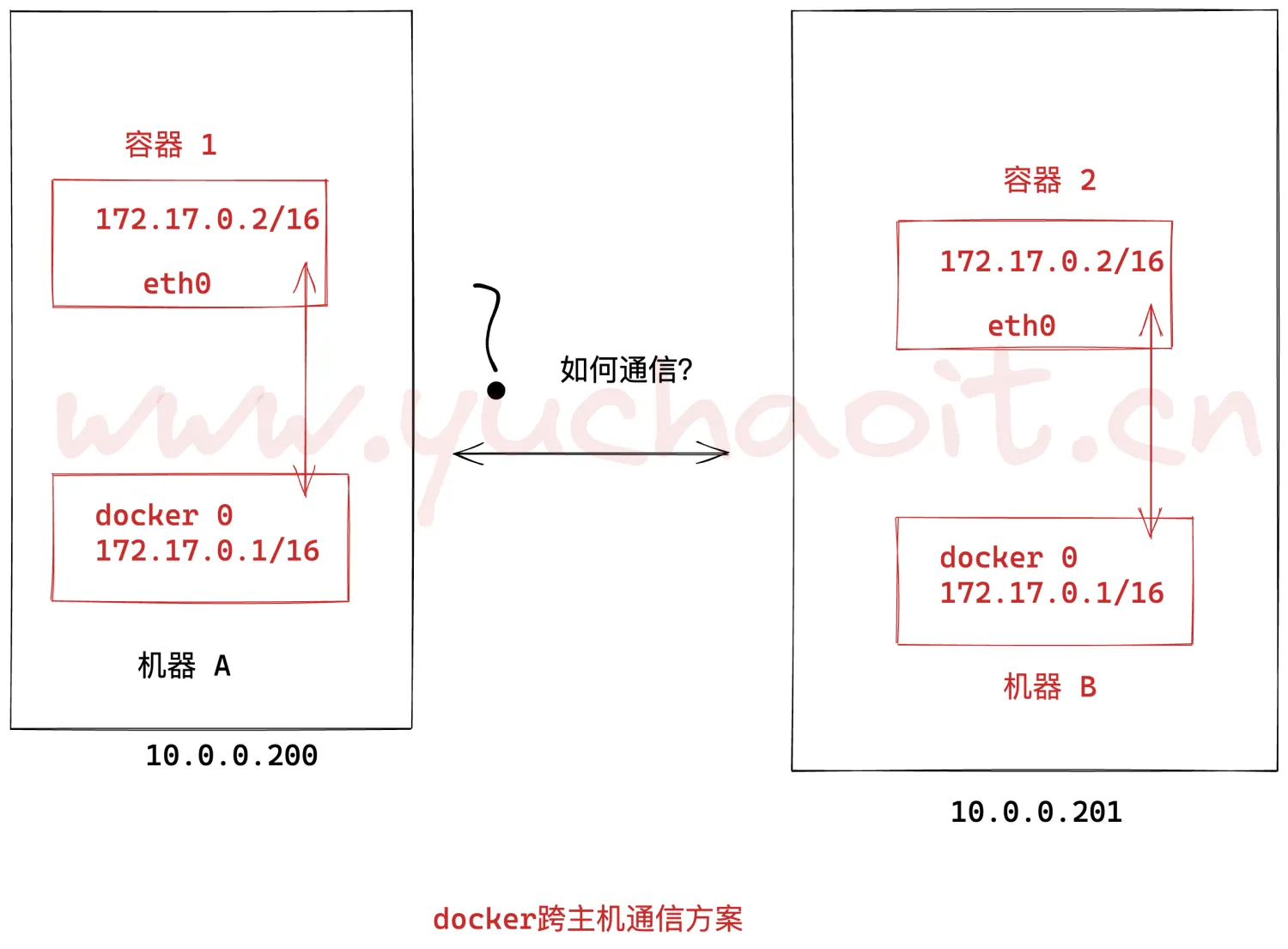
基于iptables的静态路由
此时两台主机上的Docker容器如何直接通过IP地址进行通信?
一种直接想到的方案便是通过分别在各自主机中 添加路由 来实现两个centos容器之间的直接通信。我们来试试吧
方案原理图
由于使用容器的IP进行路由,就需要避免不同主机上的容器使用了相同的IP,为此我们应该为不同的主机分配不同的子网来保证。
于是我们构造一下两个容器之间通信的路由方案,如下图所示。
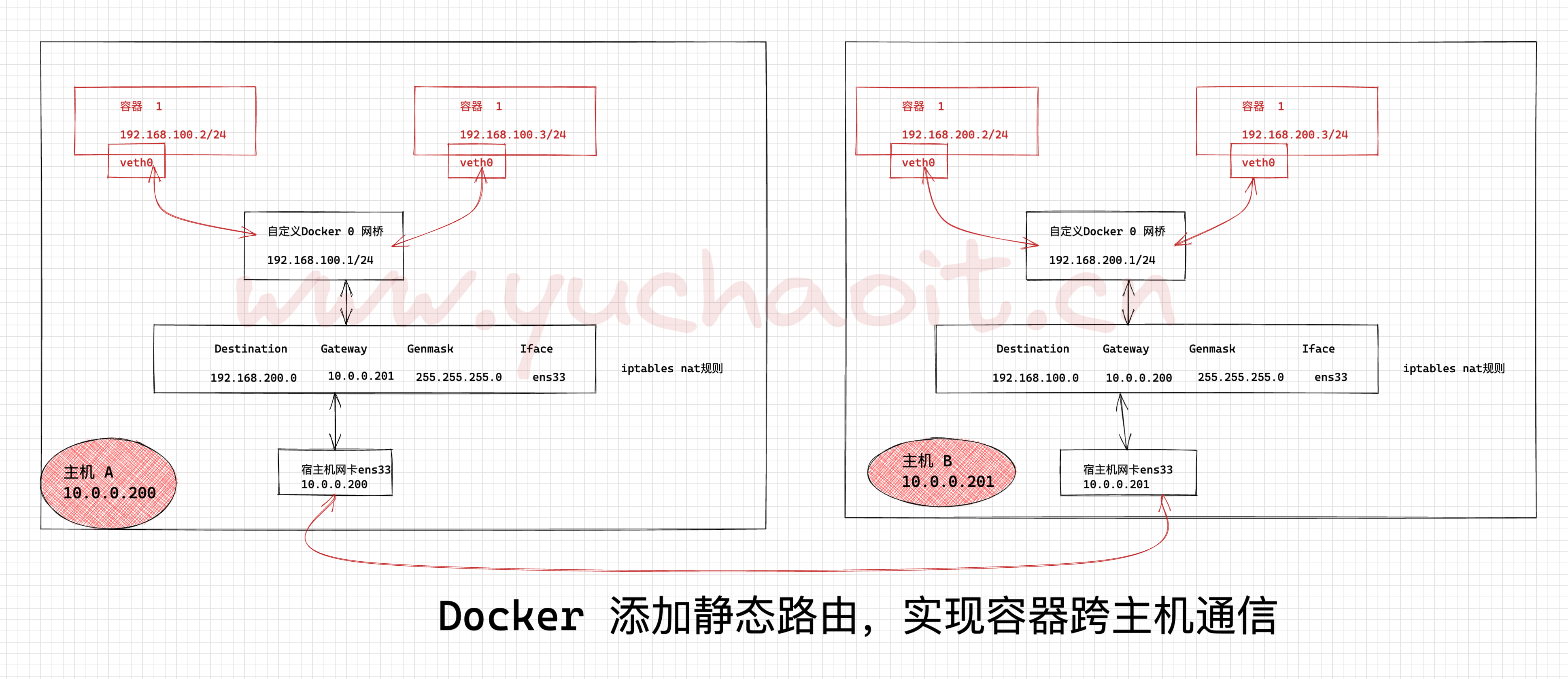
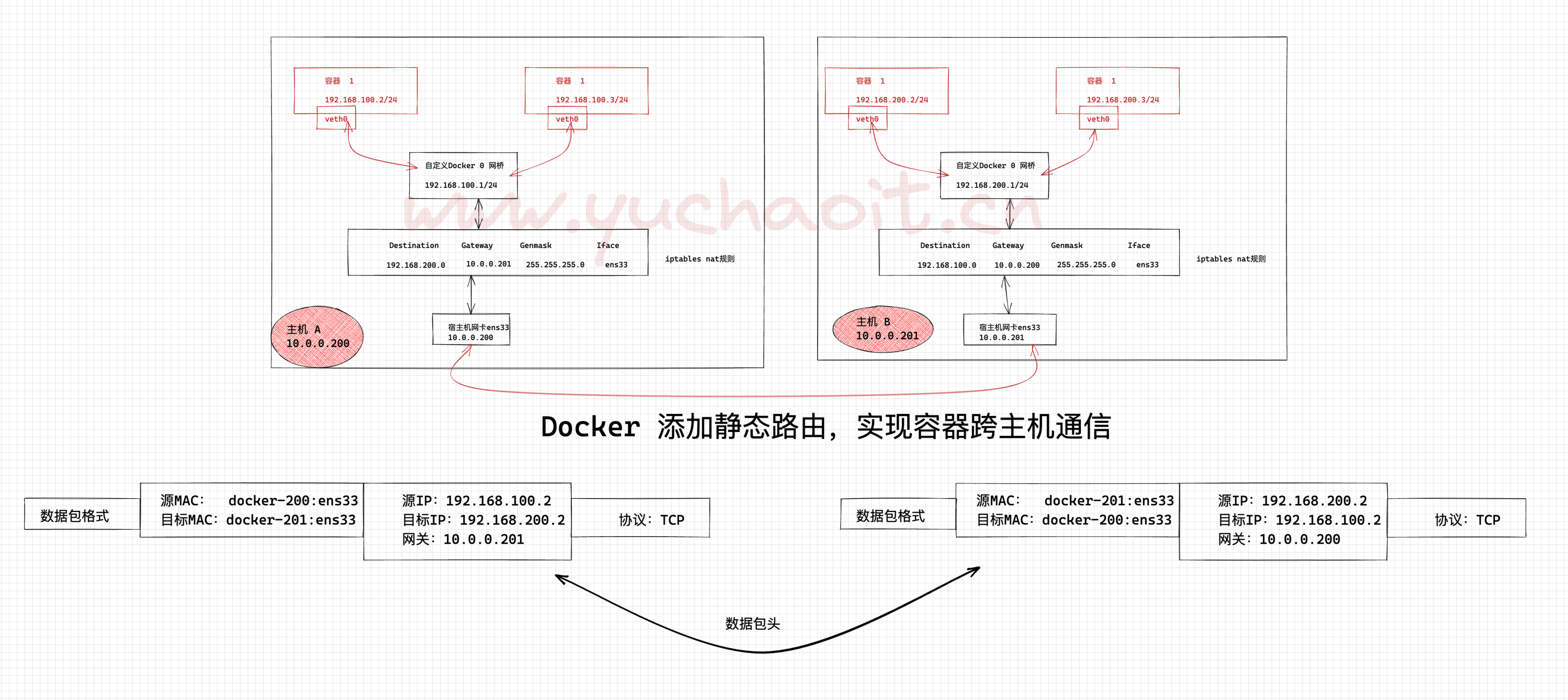
核心逻辑就是,利用iptables实现数据包转发
1. 主机A的容器数据包,网关指向机器B
数据包头
配置说明步骤
1. 两个宿主机的容器,分别有自己的网段,不得冲突了
2. 两台机器,都配置了静态路由规则,互相传递数据
3. 内核,防火墙要支持数据包转发
实践
docker-200
1.修改docker0的网段
cat> /etc/docker/daemon.json <<'EOF'
{
"bip":"192.168.100.1/24",
"registry-mirrors" : [
"https://ms9glx6x.mirror.aliyuncs.com"
],
"insecure-registries":["http://10.0.0.200"]
}
EOF
2.重载docker
systemctl daemon-reload
systemctl restart docker
ip a |grep 192.168.100
docker-201
1.修改docker0的网段
cat> /etc/docker/daemon.json <<'EOF'
{
"bip":"192.168.200.1/24",
"registry-mirrors" : [
"https://ms9glx6x.mirror.aliyuncs.com"
]
}
EOF
2.重载docker
systemctl daemon-reload
systemctl restart docker
ip a |grep 192.168.200
添加静态路由,以及iptables
docker-200
[root@docker-200 ~]#route -n
# 本机去往192.168.200.0网段的数据包,告诉它的网关是10.0.0.201,数据包的下一跳
route add -net 192.168.200.0/24 gw 10.0.0.201
[root@docker-200 ~]#route -n |grep 192.168.200
192.168.200.0 10.0.0.201 255.255.255.0 UG 0 0 0 ens33
# iptables规则,允许流量转发
iptables -A FORWARD -s 10.0.0.0/24 -j ACCEPT
Docker-201
route add -net 192.168.100.0/24 gw 10.0.0.200
iptables -A FORWARD -s 10.0.0.0/24 -j ACCEPT
启动容器测试通信
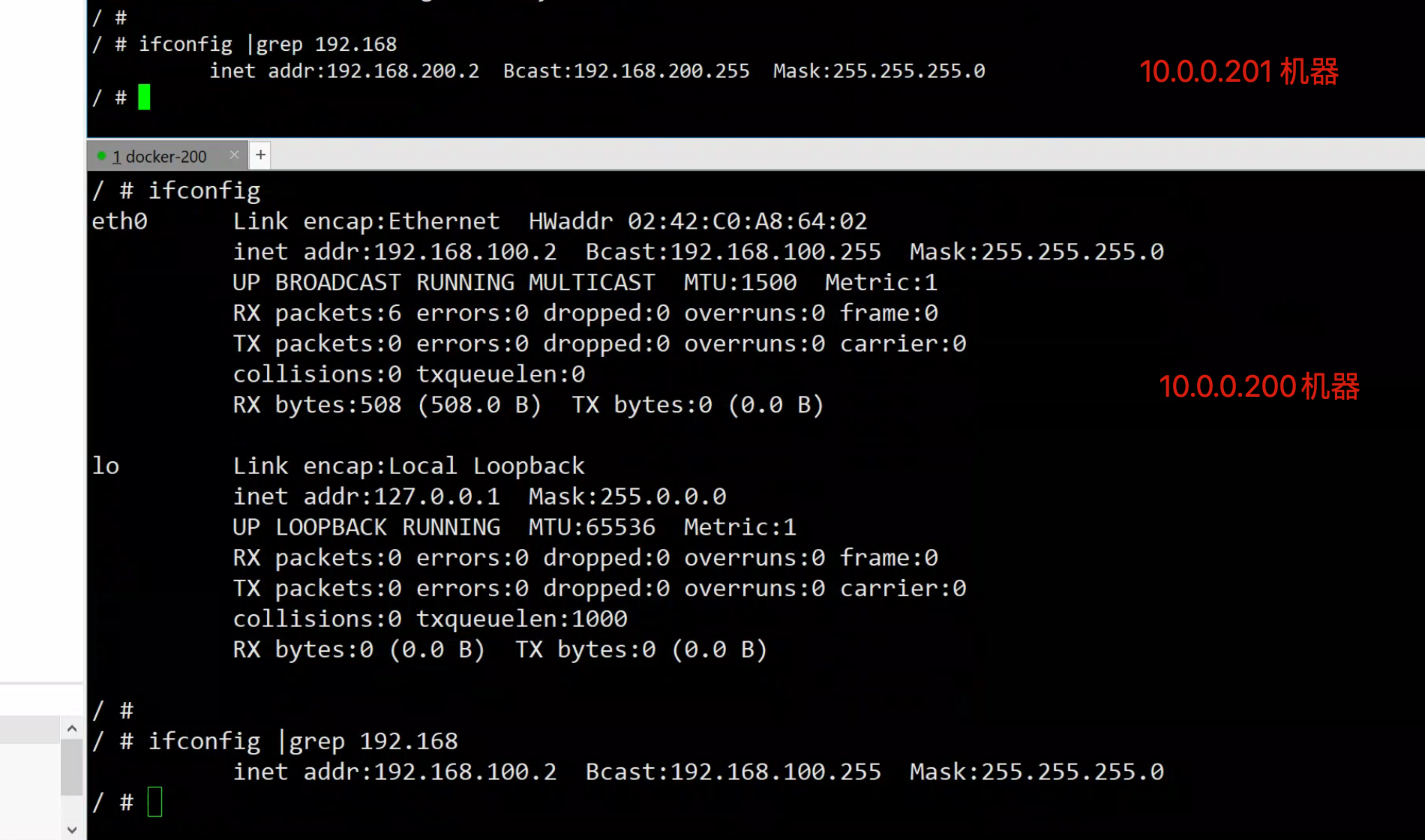
docker-200
docker run -it busybox /bin/sh
/ # ifconfig |grep 192.168
inet addr:192.168.100.2 Bcast:192.168.100.255 Mask:255.255.255.0
/ #
docker-201
[root@docker-201 ~]#docker run -it busybox /bin/sh
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
5cc84ad355aa: Pull complete
Digest: sha256:5acba83a746c7608ed544dc1533b87c737a0b0fb730301639a0179f9344b1678
Status: Downloaded newer image for busybox:latest
/ #
/ # ifconfig |grep 192.168
inet addr:192.168.200.2 Bcast:192.168.200.255 Mask:255.255.255.0
/ #
通信结果
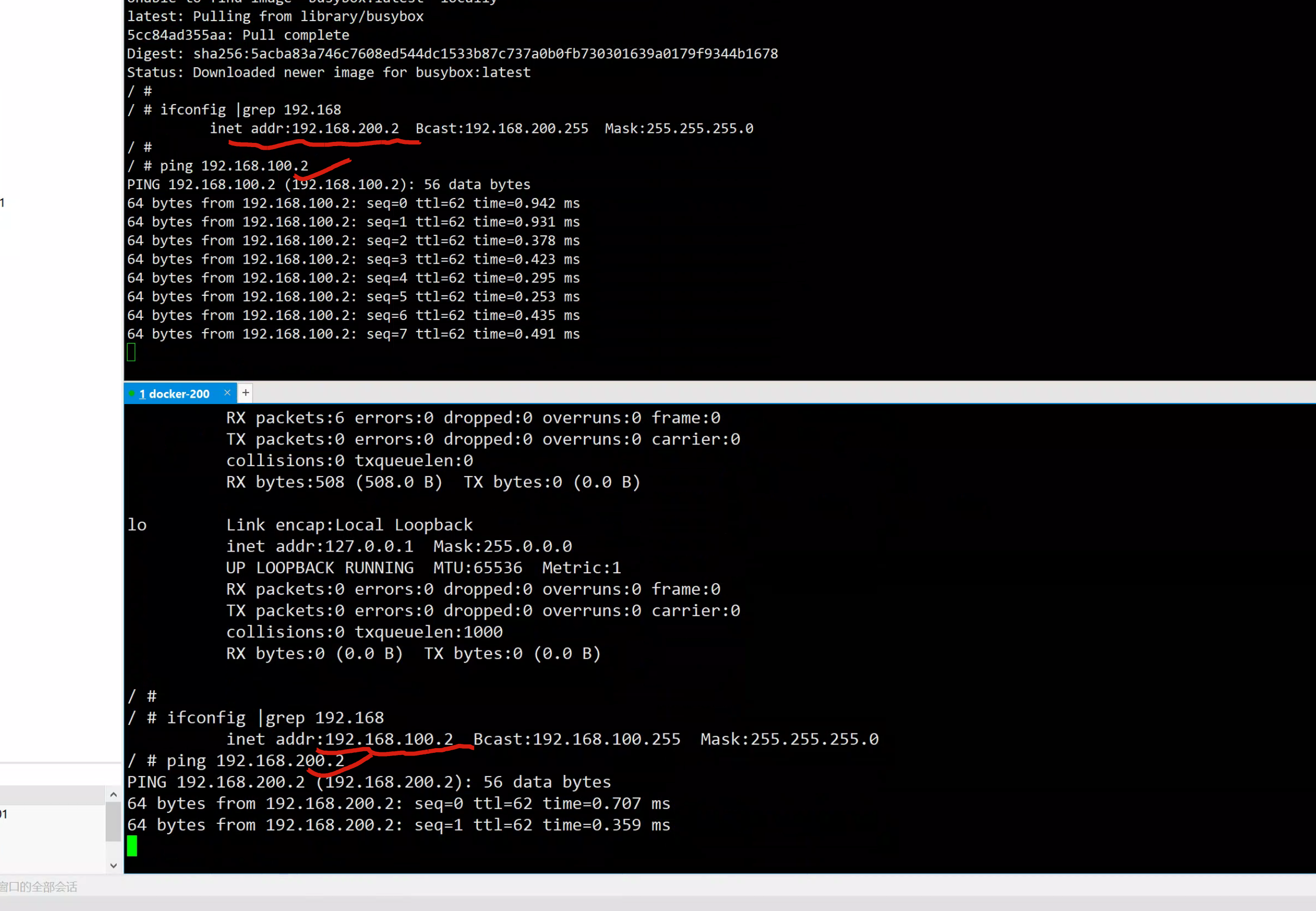
tcpdump抓取数据包
yum install tcpdump -y
17.2.6.1. 200机器
[root@docker-200 ~]#tcpdump -i ens33 -nn icmp
17.2.6.2. 201机器
[root@docker-201 ~]#tcpdump -i ens33 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
flannel实现
Flannel介绍
Flannel是 CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(Overlay Network)工具,其目的在于帮助每一个使用 Kuberentes 的 CoreOS 主机拥有一个完整的子网。 Flannel通过给每台宿主机分配一个子网的方式为容器提供虚拟网络,它基于Linux TUN/TAP,使用UDP封装IP包来创建overlay网络,并借助etcd维护网络的分配情况。
Flannel工作原理
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。但在默认的Docker配置中,每个Node的Docker服务会分别负责所在节点容器的IP分配。Node内部的容器之间可以相互访问,但是跨主机(Node)网络相互间是不能通信。Flannel设计目的就是为集群中所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得"同属一个内网"且"不重复的"IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。 Flannel 使用etcd存储配置数据和子网分配信息。flannel 启动之后,后台进程首先检索配置和正在使用的子网列表,然后选择一个可用的子网,然后尝试去注册它。etcd也存储这个每个主机对应的ip。flannel 使用etcd的watch机制监视/coreos.com/network/subnets下面所有元素的变化信息,并且根据它来维护一个路由表。为了提高性能,flannel优化了Universal TAP/TUN设备,对TUN和UDP之间的ip分片做了代理。 如下原理图:
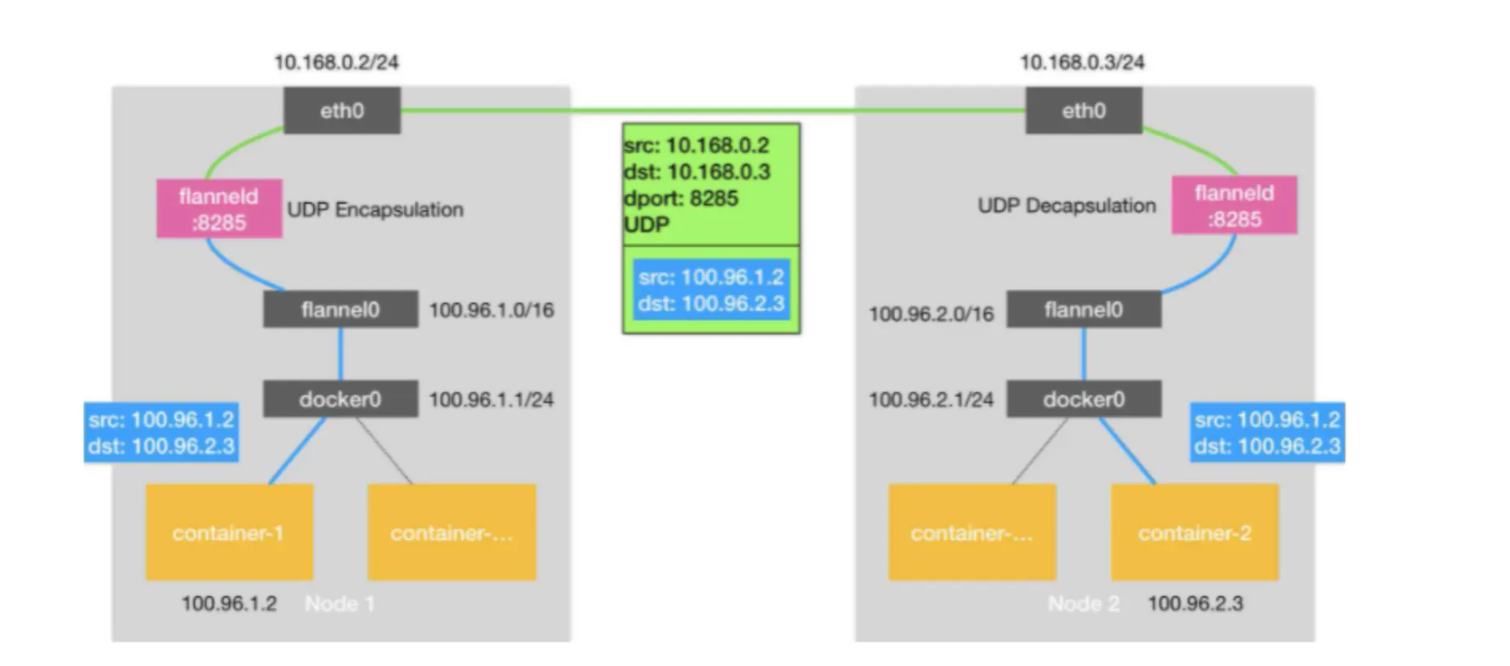
1、数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
2、Flannel通过Etcd服务维护了一张节点间的路由表,该张表里保存了各个节点主机的子网网段信息。
3、源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样的由docker0路由到达目标容器。
ETCD介绍
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
etcd作为服务发现系统,特点:
- 简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
- 安全:支持SSL证书验证
- 快速:根据官方提供的benchmark数据,单实例支持每秒2k+读操作
- 可靠:采用raft算法,实现分布式系统数据的可用性和一致性
ETCD部署
主机名称配置
hostnamectl set-hostname docker-test01
hostnamectl set-hostname docker-test02
主机名与IP地址解析
[root@docker-test01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
100.100.137.191 docker-test01
100.100.137.192 docker-test02
[root@docker-test02 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
100.100.137.191 docker-test01
100.100.137.192 docker-test02
开启内核转发
所有Docker Host
[root@docker-test01 ~]# cat /etc/sysctl.conf
net.ipv4.ip_forward=1
[root@docker-test01 ~]# sysctl -p
net.ipv4.ip_forward = 1
[root@docker-test02 ~]# cat /etc/sysctl.conf
net.ipv4.ip_forward=1
[root@docker-test02 ~]# sysctl -p
net.ipv4.ip_forward = 1
etcd安装
etcd集群
[root@docker-test01 ~]# yum -y install etcd
[root@docker-test02 ~]# yum -y install etcd
etcd配置
[root@docker-test01 ~]# cat /etc/etcd/etcd.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/node01.etcd"
#ETCD_WAL_DIR=""
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="node01"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://100.100.137.191:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://100.100.137.191:2379,http://100.100.137.191:4001"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
ETCD_INITIAL_CLUSTER="node01=http://100.100.137.191:2380,node02=http://100.100.137.192:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
#
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000"
#ETCD_PROXY_REFRESH_INTERVAL="30000"
#ETCD_PROXY_DIAL_TIMEOUT="1000"
#ETCD_PROXY_WRITE_TIMEOUT="5000"
#ETCD_PROXY_READ_TIMEOUT="0"
#
#[Security]
#ETCD_CERT_FILE=""
#ETCD_KEY_FILE=""
#ETCD_CLIENT_CERT_AUTH="false"
#ETCD_TRUSTED_CA_FILE=""
#ETCD_AUTO_TLS="false"
#ETCD_PEER_CERT_FILE=""
#ETCD_PEER_KEY_FILE=""
#ETCD_PEER_CLIENT_CERT_AUTH="false"
#ETCD_PEER_TRUSTED_CA_FILE=""
#ETCD_PEER_AUTO_TLS="false"
#
#[Logging]
#ETCD_DEBUG="false"
#ETCD_LOG_PACKAGE_LEVELS=""
#ETCD_LOG_OUTPUT="default"
#
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false"
#
#[Version]
#ETCD_VERSION="false"
#ETCD_AUTO_COMPACTION_RETENTION="0"
#
#[Profiling]
#ETCD_ENABLE_PPROF="false"
#ETCD_METRICS="basic"
#
#[Auth]
#ETCD_AUTH_TOKEN="simple"
[root@docker-test02 ~]# cat /etc/etcd/etcd.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/node02.etcd"
#ETCD_WAL_DIR=""
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="node02"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://100.100.137.192:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://100.100.137.192:2379,http://100.100.137.192:4001"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
ETCD_INITIAL_CLUSTER="node01=http://100.100.137.191:2380,node02=http://100.100.137.192:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
#
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000"
#ETCD_PROXY_REFRESH_INTERVAL="30000"
#ETCD_PROXY_DIAL_TIMEOUT="1000"
#ETCD_PROXY_WRITE_TIMEOUT="5000"
#ETCD_PROXY_READ_TIMEOUT="0"
#
#[Security]
#ETCD_CERT_FILE=""
#ETCD_KEY_FILE=""
#ETCD_CLIENT_CERT_AUTH="false"
#ETCD_TRUSTED_CA_FILE=""
#ETCD_AUTO_TLS="false"
#ETCD_PEER_CERT_FILE=""
#ETCD_PEER_KEY_FILE=""
#ETCD_PEER_CLIENT_CERT_AUTH="false"
#ETCD_PEER_TRUSTED_CA_FILE=""
#ETCD_PEER_AUTO_TLS="false"
#
#[Logging]
#ETCD_DEBUG="false"
#ETCD_LOG_PACKAGE_LEVELS=""
#ETCD_LOG_OUTPUT="default"
#
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false"
#
#[Version]
#ETCD_VERSION="false"
#ETCD_AUTO_COMPACTION_RETENTION="0"
#
#[Profiling]
#ETCD_ENABLE_PPROF="false"
#ETCD_METRICS="basic"
#
#[Auth]
#ETCD_AUTH_TOKEN="simple"
启动etcd服务
[root@docker-test01 ~]# systemctl enable etcd
[root@docker-test01 ~]# systemctl start etcd
[root@docker-test02 ~]# systemctl enable etcd
[root@docker-test02 ~]# systemctl start etcd
检查端口状态
[root@docker-test01 ~]# netstat -tnlp | grep -E "4001|2380"
tcp6 0 0 :::2380 :::* LISTEN 15549/etcd
tcp6 0 0 :::4001 :::* LISTEN 15549/etcd
检查etcd集群是否健康
[root@docker-test01 ~]# etcdctl -C http://100.100.137.191:2379 cluster-health
member 68b9ecb82327039a is healthy: got healthy result from http://100.100.137.191:2379
member e50b751caa84ac54 is healthy: got healthy result from http://100.100.137.192:2379
cluster is healthy
[root@docker-test01 ~]# etcdctl member list
68b9ecb82327039a: name=node01 peerURLs=http://100.100.137.191:2380 clientURLs=http://100.100.137.191:2379,http://100.100.137.191:4001 isLeader=true
e50b751caa84ac54: name=node02 peerURLs=http://100.100.137.192:2380 clientURLs=http://100.100.137.192:2379,http://100.100.137.192:4001 isLeader=false
Flannel部署
Flannel安装
[root@docker-test01 ~]# yum -y install flannel
[root@docker-test02 ~]# yum -y install flannel
修改Flannel配置文件
[root@docker-test01 ~]# cat /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://100.100.137.191:2379,http://100.100.137.192:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/flannel_use/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
[root@docker-test02 ~]# cat /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://100.100.137.191:2379,http://100.100.137.192:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/flannel_use/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
配置etcd中关于flannel的key
注释: 此(flannel_use)目录自己可以定义,但是此处设置的目录必须与flannel配置文件中FLANNEL_ETCD_PREFIX="/flannel_use/network"配置保持一致,flannel启动程序只认带“config”的key,否则会报错Not a directory (/flannel_use/network)】
该ip网段可以任意设定,随便设定一个网段都可以。不要和现有的网段冲突即可,容器的ip就是根据这个网段进行自动分配的,ip分配后,容器一般是可以对外联网的(网桥模式,只要Docker Host能上网即可。)
[root@docker-test01 ~]# etcdctl set /flannel_use/network/config '{"Network":"10.10.0.0/16"}'
[root@docker-test01 ~]# etcdctl get /flannel_use/network/config
{"Network":"10.10.0.0/16"}
启动Flannel服务
[root@docker-test01 ~]# systemctl enable flanneld;systemctl start flanneld
[root@docker-test02 ~]# systemctl enable flanneld;systemctl start flanneld
查看各node中flannel产生的配置信息
[root@docker-test01 ~]# ls /run/flannel/
docker subnet.env
[root@docker-test01 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.10.0.0/16
FLANNEL_SUBNET=10.10.97.1/24
FLANNEL_MTU=1472
FLANNEL_IPMASQ=false
[root@docker-test01 ~]# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens34: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:a8:82:45 brd ff:ff:ff:ff:ff:ff
inet 100.100.137.191/24 brd 100.100.137.255 scope global noprefixroute ens34
valid_lft forever preferred_lft forever
inet6 fe80::1a68:a106:a2d0:8033/64 scope link noprefixroute
valid_lft forever preferred_lft forever
18: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.10.97.0/16 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::dc1:42d6:4feb:ea53/64 scope link flags 800
valid_lft forever preferred_lft forever
[root@docker-test02 ~]# ls /run/flannel/
docker subnet.env
[root@docker-test02 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.10.0.0/16
FLANNEL_SUBNET=10.10.73.1/24
FLANNEL_MTU=1472
FLANNEL_IPMASQ=false
[root@docker-test02 ~]# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:52:5a:07 brd ff:ff:ff:ff:ff:ff
inet 100.100.137.192/24 brd 100.100.137.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::91ed:a0dd:a818:214d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
17: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.10.73.0/16 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::5be5:bfe8:f0e2:7e39/64 scope link flags 800
valid_lft forever preferred_lft forever
Docker网络配置
修改docker启动命令:
[root@docker-test01 ~]# cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target docker.socket firewalld.service containerd.service time-set.target
Wants=network-online.target containerd.service
Requires=docker.socket
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock $DOCKER_NETWORK_OPTIONS #这里添加结尾命令
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutStartSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
# Older systemd versions default to a LimitNOFILE of 1024:1024, which is insufficient for many
# applications including dockerd itself and will be inherited. Raise the hard limit, while
# preserving the soft limit for select(2).
LimitNOFILE=1024:524288
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
OOMScoreAdjust=-500
[Install]
WantedBy=multi-user.target
[root@docker-test01 ~]# systemctl daemon-reload
[root@docker-test01 ~]# systemctl restart docker
[root@docker-test01 ~]# ip a s
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:3e:31:b7:b5 brd ff:ff:ff:ff:ff:ff
inet 10.10.97.1/24 brd 10.10.97.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:3eff:fe31:b7b5/64 scope link
valid_lft forever preferred_lft forever
18: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.10.97.0/16 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::dc1:42d6:4feb:ea53/64 scope link flags 800
valid_lft forever preferred_lft forever
[root@docker-test02 ~]# cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target docker.socket firewalld.service containerd.service time-set.target
Wants=network-online.target containerd.service
Requires=docker.socket
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock $DOCKER_NETWORK_OPTIONS #这里添加结尾命令
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutStartSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
# Older systemd versions default to a LimitNOFILE of 1024:1024, which is insufficient for many
# applications including dockerd itself and will be inherited. Raise the hard limit, while
# preserving the soft limit for select(2).
LimitNOFILE=1024:524288
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
OOMScoreAdjust=-500
[Install]
WantedBy=multi-user.target
[root@docker-test02 ~]# systemctl daemon-reload
[root@docker-test02 ~]# systemctl restart docker
[root@docker-test02 ~]# ip a s
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:6b:45:85:22 brd ff:ff:ff:ff:ff:ff
inet 10.10.73.1/24 brd 10.10.73.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:6bff:fe45:8522/64 scope link
valid_lft forever preferred_lft forever
17: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.10.73.0/16 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::5be5:bfe8:f0e2:7e39/64 scope link flags 800
valid_lft forever preferred_lft forever
跨Docker Host容器间通信验证
[root@docker-test01 ~]# docker run -it --rm 47.93.86.49:80/test/busybox:latest
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:0A:0A:61:02
inet addr:10.10.97.2 Bcast:10.10.97.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1472 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:656 (656.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 10.10.73.2
PING 10.10.73.2 (10.10.73.2): 56 data bytes
64 bytes from 10.10.73.2: seq=0 ttl=60 time=4.020 ms
64 bytes from 10.10.73.2: seq=1 ttl=60 time=1.035 ms
^C
--- 10.10.73.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 1.035/2.527/4.020 ms
[root@docker-test02 ~]# docker run -it --rm 47.93.86.49:80/test/busybox:latest
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:0A:0A:49:02
inet addr:10.10.73.2 Bcast:10.10.73.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1472 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:656 (656.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 10.10.97.2
PING 10.10.97.2 (10.10.97.2): 56 data bytes
64 bytes from 10.10.97.2: seq=0 ttl=60 time=1.861 ms
64 bytes from 10.10.97.2: seq=1 ttl=60 time=1.524 ms
^C
--- 10.10.97.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 1.524/1.692/1.861 ms
基于macvlan实现
参考资料
https://ipwithease.com/what-is-macvlan/

macvlan 用于 Docker 网络
如何理解macvlan技术
这种技术原理是 将物理网卡(ens33)虚拟成多个网卡
需要linux内核支持3.9+
[root@docker-200 ~]#lsmod |grep macvlan
macvlan 19239 1 macvtap
macvlan默认使用bridge模式,实现数据包转发。
这里更多是属于云计算网络的知识范畴。
在 Docker 中,macvlan 是众多 Docker 网络模型中的一种,并且是一种跨主机的网络模型,作为一种驱动(driver)启用(-d 参数指定)
Docker macvlan 只支持 bridge 模式。
首先准备两个主机节点的 Docker 环境,搭建如下拓扑图示:
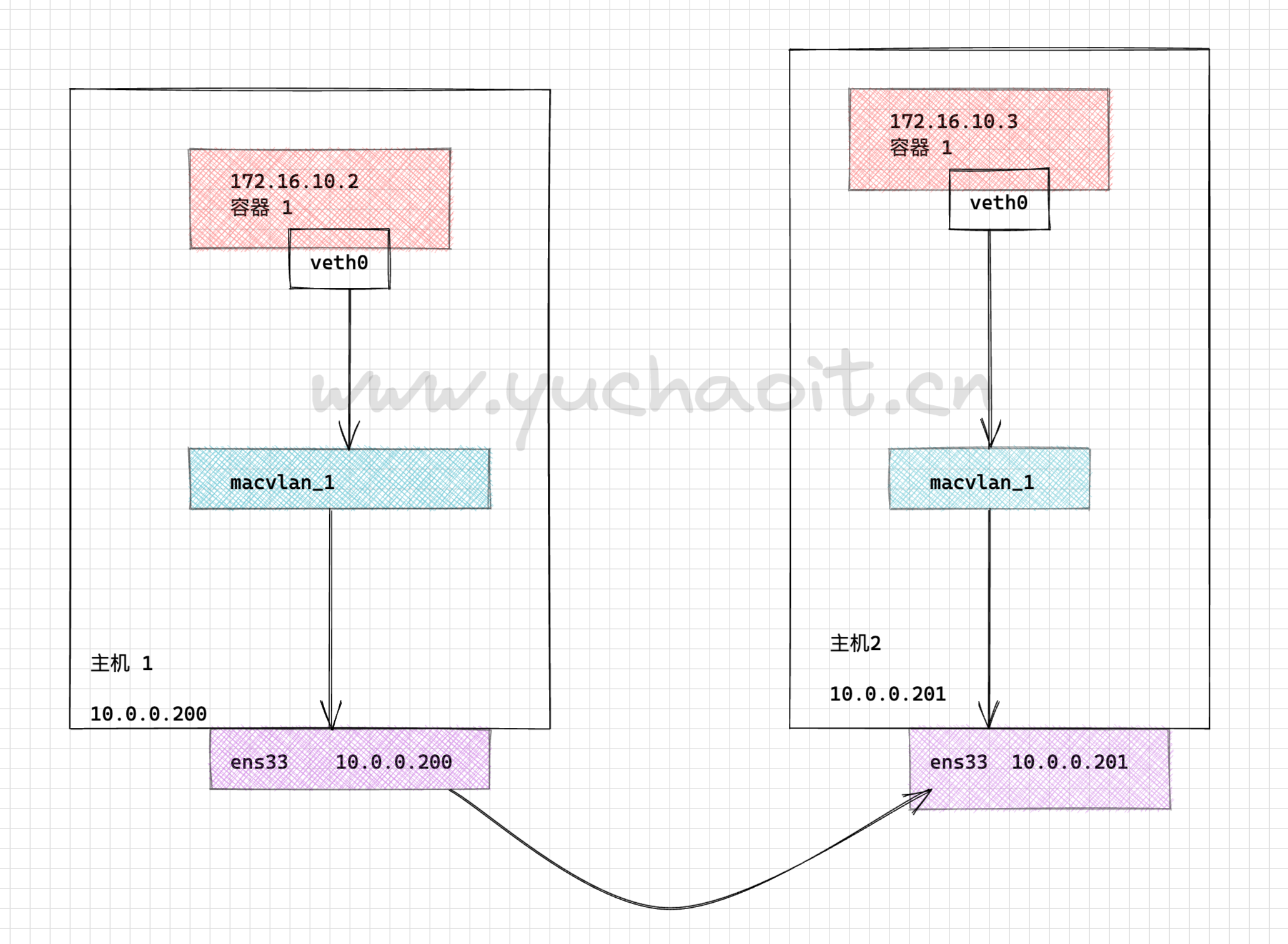
创建基于同一个macvlan网段的通信
分别在2个主机执行命令,创建macvlan网络环境即可
docker network create -d macvlan --subnet=172.16.10.0/24 --gateway=172.16.10.1 -o parent=ens33 macvlan_1
这条命令中,
-d 指定 Docker 网络 driver
--subnet 指定 macvlan 网络所在的网络
--gateway 指定网关
-o parent 指定用来分配 macvlan 网络的物理网卡
之后可以看到当前主机的网络环境,其中出现了 macvlan 网络:
[root@docker-200 ~]#docker network ls
NETWORK ID NAME DRIVER SCOPE
266e88b88c07 bridge bridge local
f3971eca0c0f host host local
ca0e2d298a44 macvlan_1 macvlan local
ff6208d689fb none null local

分别启动两个机器的容器
docker-200 启动容器,且指定用macvlan网络
--ip 指定容器 c1 使用的 IP,这样做的目的是防止自动分配,造成 IP 冲突
--network 指定 macvlan 网络
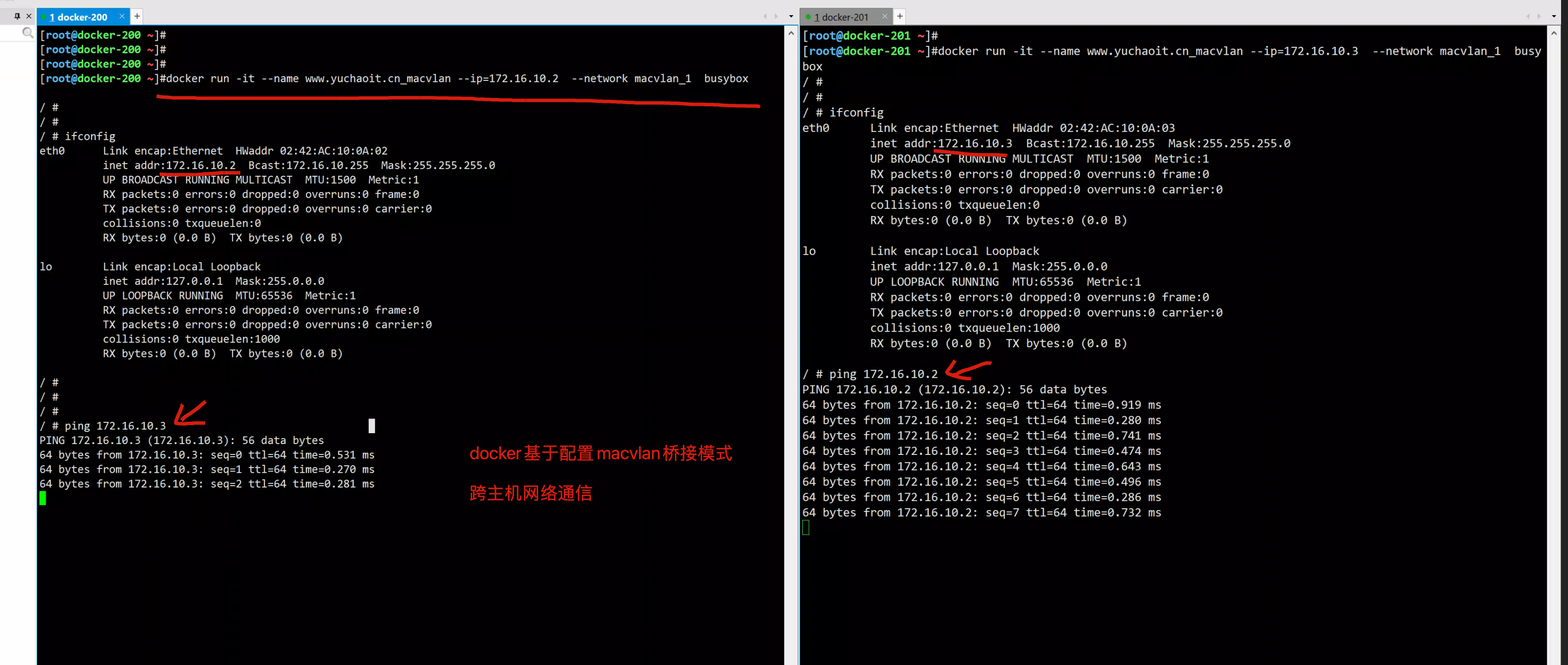
docker run -it --name www.yuchaoit.cn_macvlan --ip=172.16.10.2 --network macvlan_1 busybox
docker-201机器
docker run -it --name www.yuchaoit.cn_macvlan --ip=172.16.10.3 --network macvlan_1 busybox
抓包看数据包走向
[root@docker-200 ~]#tcpdump -i ens33 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
01:14:20.937537 IP 172.16.10.3 > 172.16.10.2: ICMP echo request, id 8, seq 73, length 64
01:14:20.937569 IP 172.16.10.2 > 172.16.10.3: ICMP echo reply, id 8, seq 73, length 64
01:14:21.169355 IP 172.16.10.2 > 172.16.10.3: ICMP echo request, id 8, seq 68, length 64
01:14:21.170491 IP 172.16.10.3 > 172.16.10.2: ICMP echo reply, id 8, seq 68, length 64
可见,是直接基于ens33网卡转发的流量
macvlan还支持不同网段之间的连接
consul注册中心实现
官网
https://www.consul.io/docs
https://www.consul.io/docs/intro/usecases/what-is-a-service-mesh 服务网格
二进制部署consul
[root@docker-200 ~]#
[root@docker-200 ~]#wget https://releases.hashicorp.com/consul/1.4.4/consul_1.4.4_linux_amd64.zip
--2022-08-30 01:28:19-- https://releases.hashicorp.com/consul/1.4.4/consul_1.4.4_linux_amd64.zip
Resolving releases.hashicorp.com (releases.hashicorp.com)... 13.249.167.10, 13.249.167.20, 13.249.167.41, ...
Connecting to releases.hashicorp.com (releases.hashicorp.com)|13.249.167.10|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 34755554 (33M) [application/zip]
Saving to: ‘consul_1.4.4_linux_amd64.zip’
100%[===========================================================================>] 34,755,554 19.8MB/s in 1.7s
2022-08-30 01:28:22 (19.8 MB/s) - ‘consul_1.4.4_linux_amd64.zip’ saved [34755554/34755554]
[root@docker-200 ~]#
[root@docker-200 ~]#
[root@docker-200 ~]#unzip consul_1.4.4_linux_amd64.zip
Archive: consul_1.4.4_linux_amd64.zip
inflating: consul
[root@docker-200 ~]#
[root@docker-200 ~]#mv consul /usr/bin/consul
[root@docker-200 ~]#
[root@docker-200 ~]#chmod +x /usr/bin/consul
[root@docker-200 ~]#
[root@docker-200 ~]#consul -v
Consul v1.4.4
Protocol 2 spoken by default, understands 2 to 3 (agent will automatically use protocol >2 when speaking to compatible agents)
[root@docker-200 ~]#
[root@docker-200 ~]#
后台运行consul
[root@docker-200 ~]#nohup consul agent -server -bootstrap -ui -data-dir /var/lib/consul -client=10.0.0.200 -bind=10.0.0.200 &>/var/log/consul.log &
[1] 51445
$ 检查consul运行
[root@docker-200 ~]#jobs -l
[1]+ 51445 Running nohup consul agent -server -bootstrap -ui -data-dir /var/lib/consul -client=10.0.0.200 -bind=10.0.0.200 &>/var/log/consul.log &
[root@docker-200 ~]#
查看运行日志
tail -f /var/log/consul.log
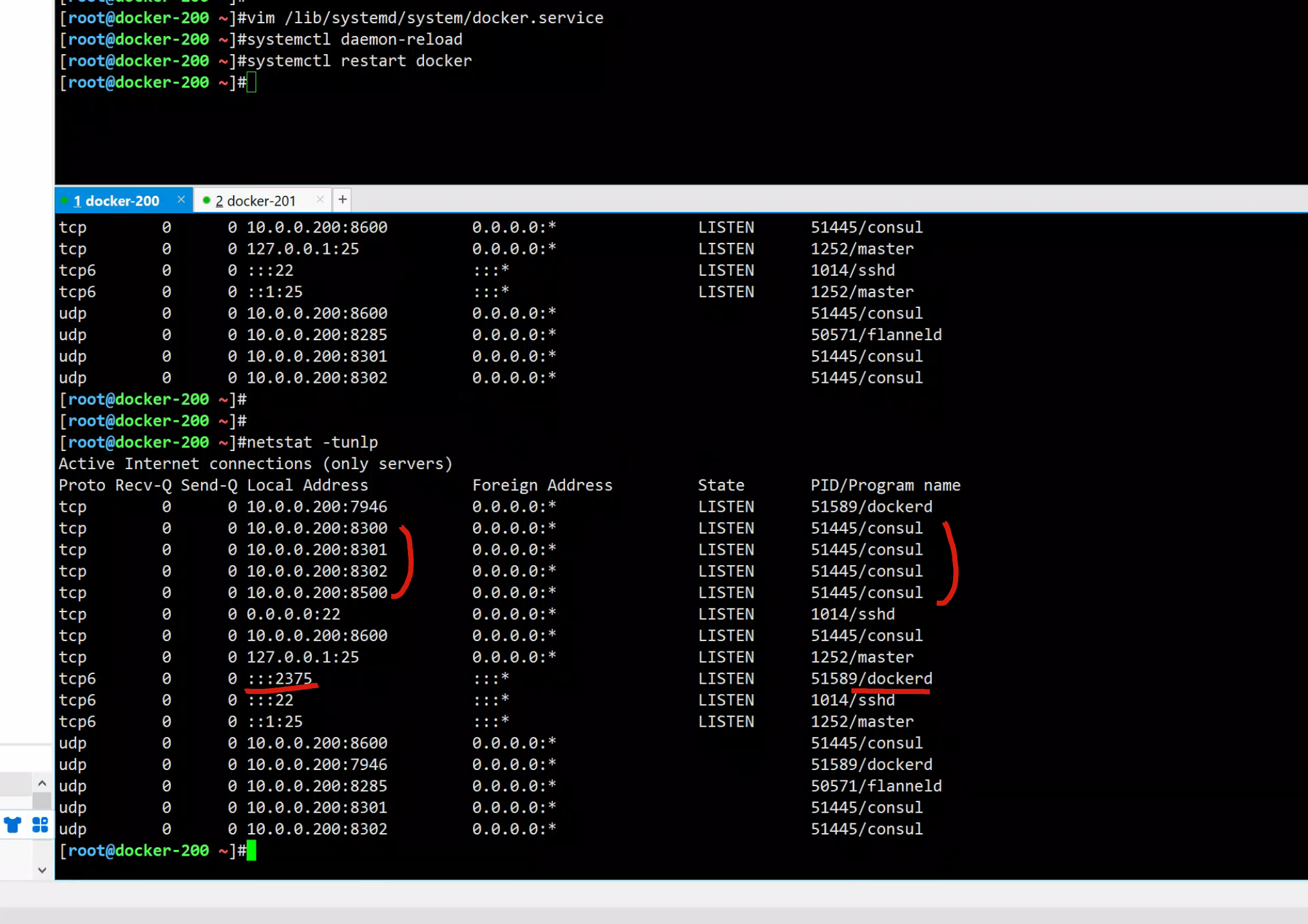
docker-200修改docker启动文件
# 注意去掉flannel的配置
[root@docker-200 ~]#vim /lib/systemd/system/docker.service
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
containerd=/run/containerd/containerd.sock
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store consul://10.0.0.200:8500 --cluster-advertise 10.0.0.200:2375
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
重启docker-200
[root@docker-200 ~]#systemctl daemon-reload
[root@docker-200 ~]#systemctl restart docker
[root@docker-200 ~]#
同样的重启docker201
修改当前机器docker地址信息即可。
# 参数
--cluster-store 指定了consul服务发现地址
--cluster-advertise 指定了本机服务注册地址,也可以用本机内网地址10.0.0.x代替
# 2375:未加密的docker socket,远程root无密码访问主机
# 表示将docker暴露在可访问的tcp的2375端口,通过ip:port远程管理docker
# 然后将自己的信息,注册到consul里 10.0.0.200:8500
#########
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
containerd=/run/containerd/containerd.sock
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store consul://10.0.0.200:8500 --cluster-advertise 10.0.0.201:2375
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
重启
#
[root@docker-201 ~]#vim /lib/systemd/system/docker.service
[root@docker-201 ~]#systemctl daemon-reload
[root@docker-201 ~]#systemctl restart docker
访问consul-ui
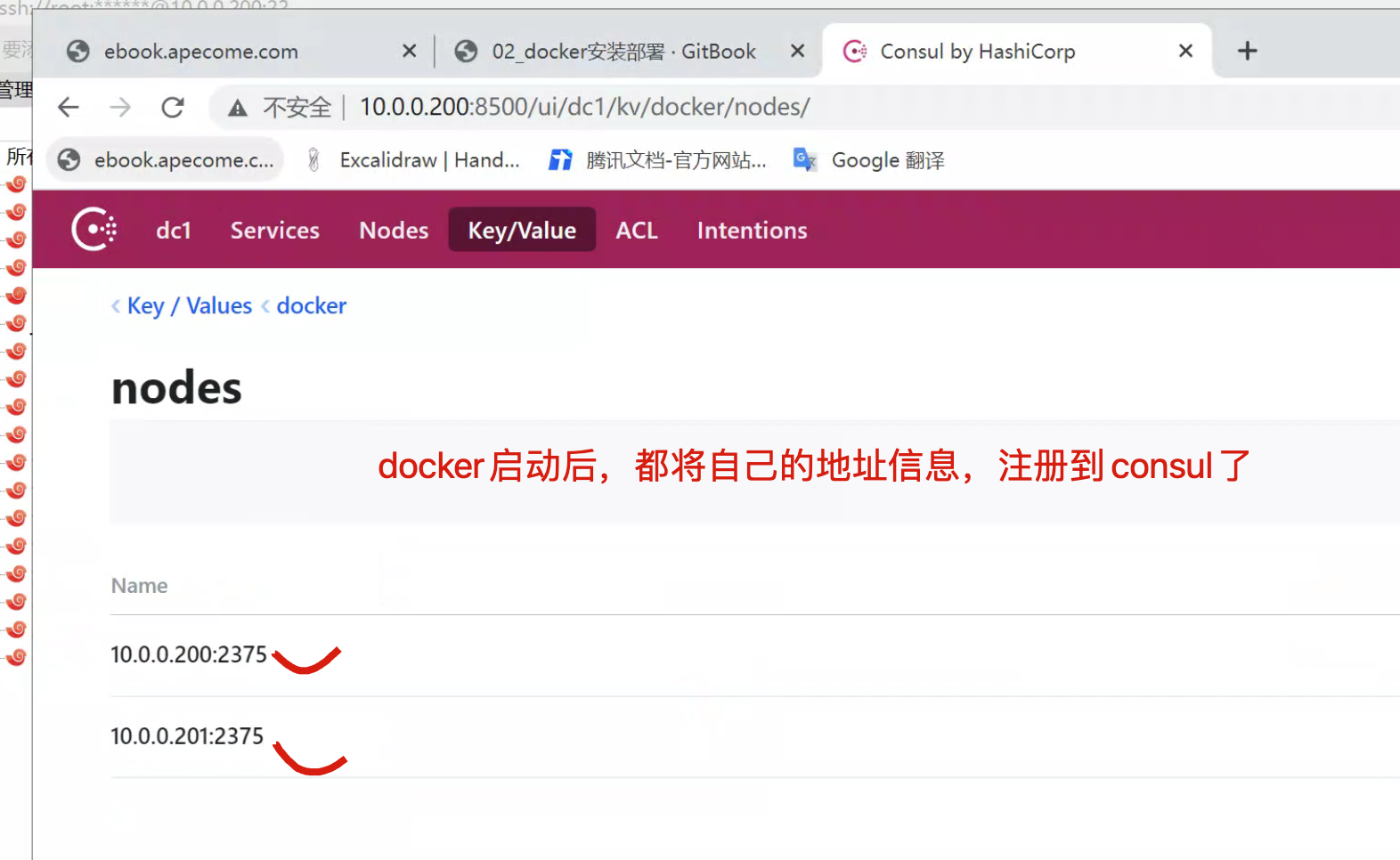
创建完后通过浏览器访问一下,可以看到这两台会自动注册上来,这样的话这两个主机之间就会进行通信。
容器网络了解(关于docker内置的overlay网络)
DOCKER的内置OVERLAY网络
内置跨主机的网络通信一直是Docker备受期待的功能,在1.9版本之前,社区中就已经有许多第三方的工具或方法尝试解决这个问题,例如Macvlan、Pipework、Flannel、Weave等。
虽然这些方案在实现细节上存在很多差异,但其思路无非分为两种: 二层VLAN网络和Overlay网络
简单来说,二层VLAN网络解决跨主机通信的思路是把原先的网络架构改造为互通的大二层网络,通过特定网络设备直接路由,实现容器点到点的之间通信。这种方案在传输效率上比Overlay网络占优,然而它也存在一些固有的问题。
这种方法需要二层网络设备支持,通用性和灵活性不如后者。
由于通常交换机可用的VLAN数量都在4000个左右,这会对容器集群规模造成限制,远远不能满足公有云或大型私有云的部署需求; 大型数据中心部署VLAN,会导致任何一个VLAN的广播数据会在整个数据中心内泛滥,大量消耗网络带宽,带来维护的困难。
相比之下,Overlay网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在IP报文之上的新的数据格式。这样不但能够充分利用成熟的IP路由协议进程数据分发;而且在Overlay技术中采用扩展的隔离标识位数,能够突破VLAN的4000数量限制支持高达16M的用户,并在必要时可将广播流量转化为组播流量,避免广播数据泛滥。
因此,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案。
容器在两个跨主机进行通信的时候,是使用overlay network这个网络模式进行通信;如果使用host也可以实现跨主机进行通信,直接使用这个物理的ip地址就可以进行通信。overlay它会虚拟出一个网络比如10.0.2.3这个ip地址。在这个overlay网络模式里面,有一个类似于服务网关的地址,然后把这个包转发到物理服务器这个地址,最终通过路由和交换,到达另一个服务器的ip地址。
图解overlay+consul实现跨主机网络通信
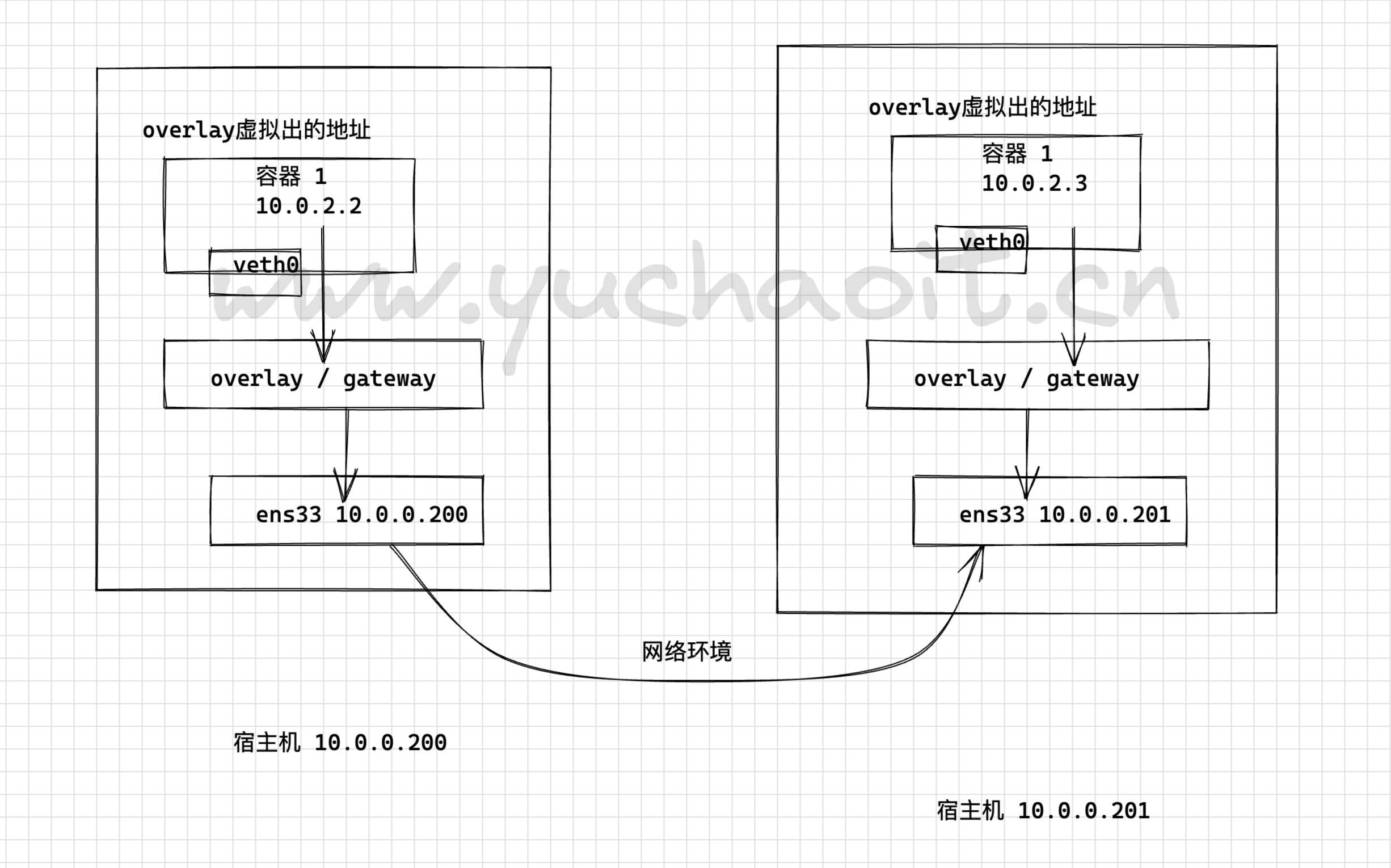
要实现overlay网络,我们会有一个服务发现。
比如说consul,会定义一个ip地址池,比如10.0.2.0/24之类的。
上面会有容器,容器的ip地址会从上面去获取。
获取完了后,会通过ens33来进行通信,这样就实现跨主机的通信。
docker-200创建overlay网络
[root@docker-200 ~]#docker network create -d overlay --subnet=10.0.2.1/24 www.yuchaoit.cn_overlay_net
5989e980ca834bf84257938c5dc533401a398e06db2ecba67c2f8763f5f5fdcb
[root@docker-200 ~]#docker network ls
NETWORK ID NAME DRIVER SCOPE
dfb82c33d669 bridge bridge local
f3971eca0c0f host host local
ca0e2d298a44 macvlan_1 macvlan local
ff6208d689fb none null local
5989e980ca83 www.yuchaoit.cn_overlay_net overlay global
[root@docker-200 ~]#
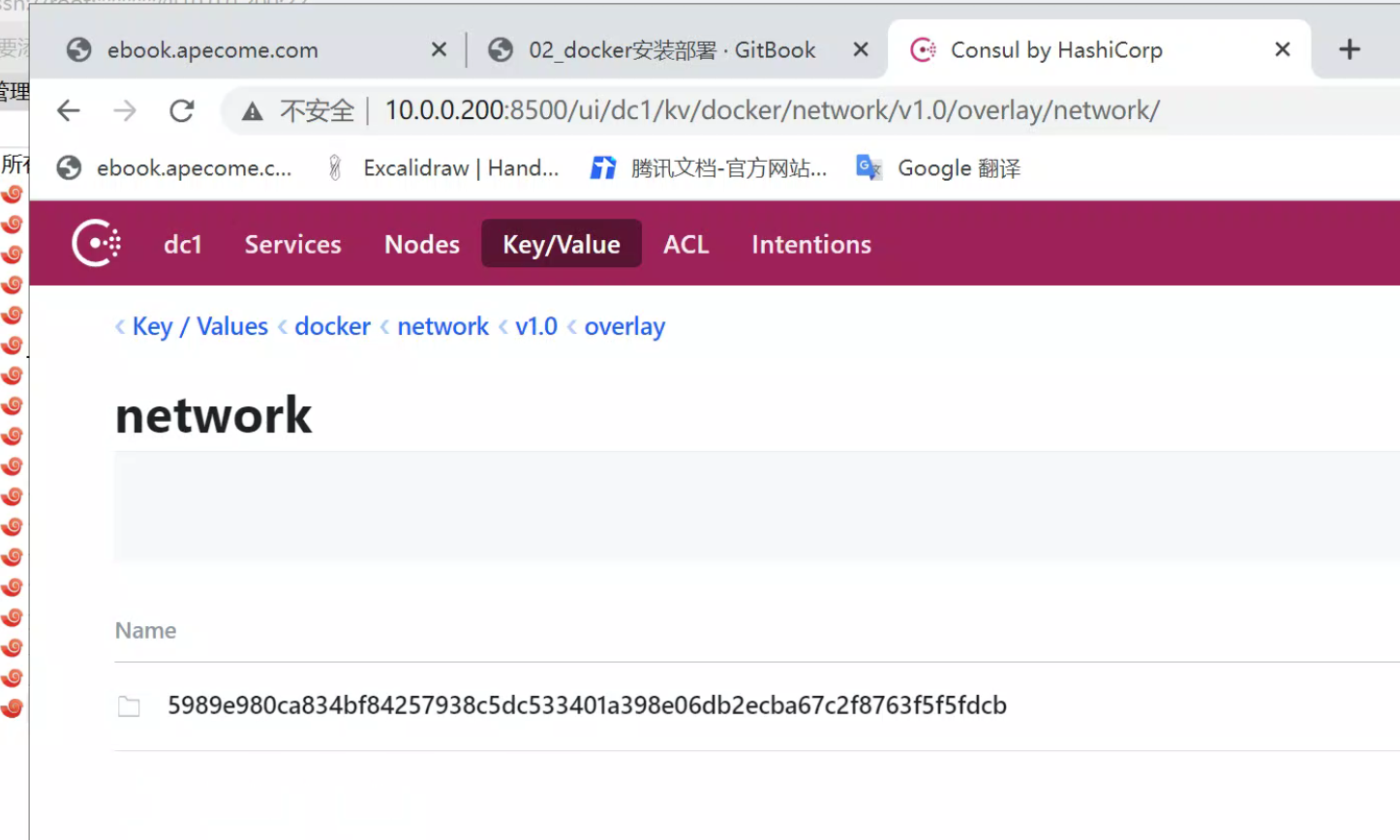
在docker-200上创建的网络信息,会立即同步到docker-201上。
consul任意节点配置的k/v 都会同步到其他节点。
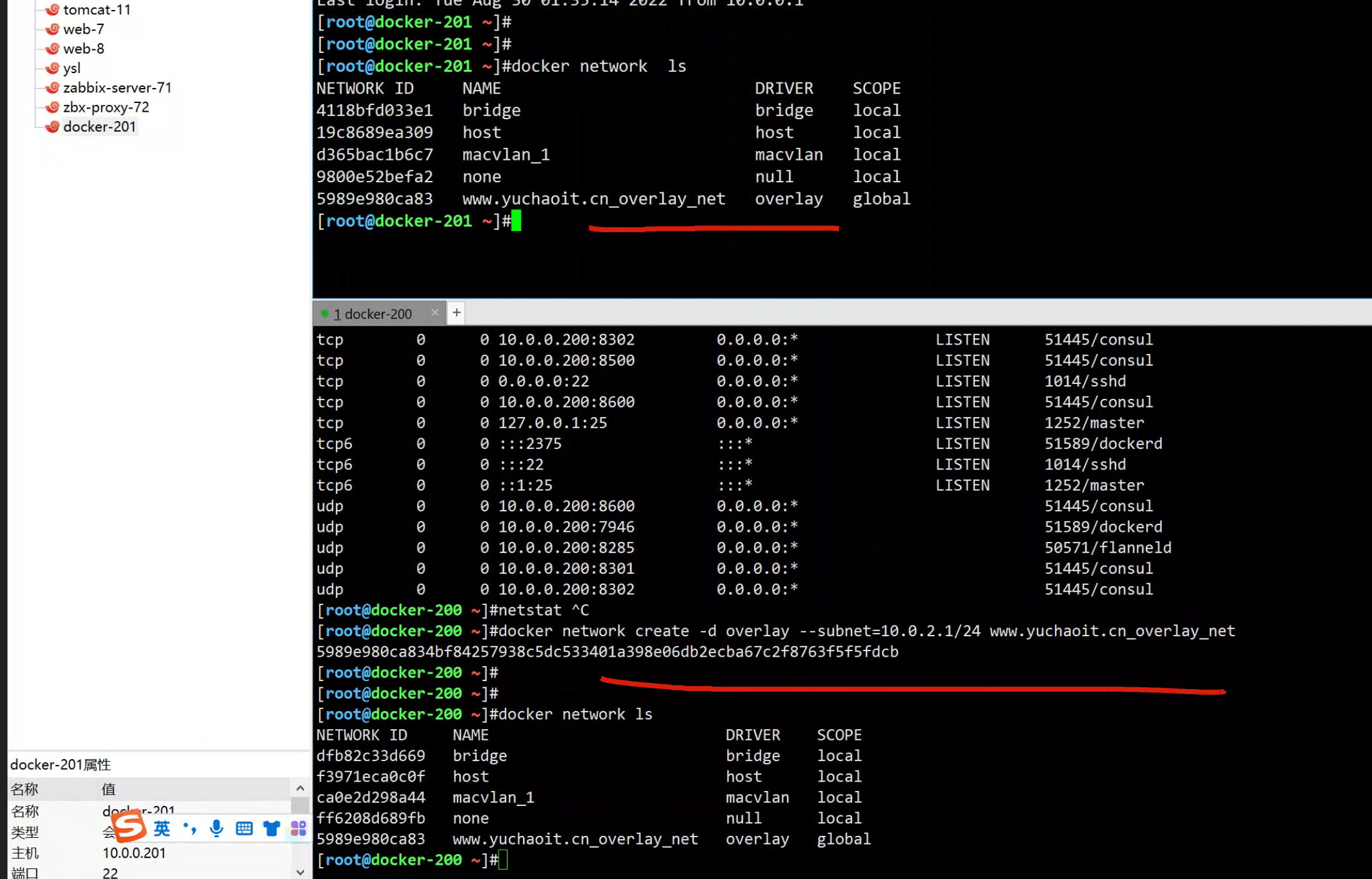
在docker-200上创建的网络信息,会立即同步到docker-201上。 consul任意节点配置的k/v 都会同步到其他节点。
测试跨主机的通信
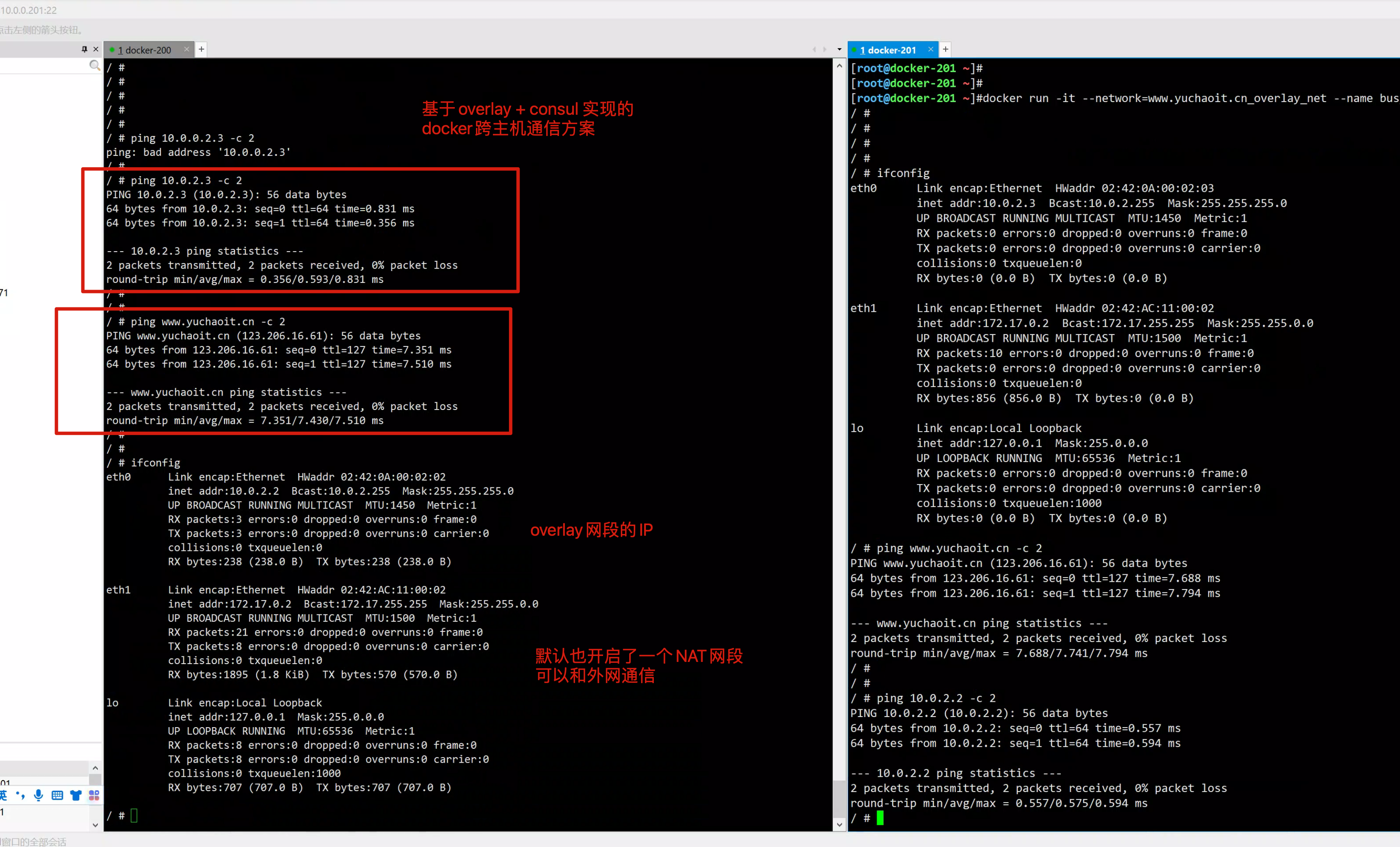
到此,我们这里实现了跨主机通信,是通过overlay network这种网络模式进行通信的。